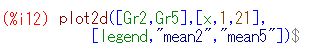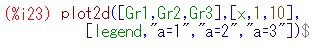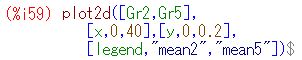「Maxima」を活用して数学の学習ロードを駆け抜けよう!
(注) MathJaxを使用しているので、 スマホでは表示に時間がかかることがあります。
モバイル利用(Android)でのメニュー選択は、 SiteMapを利用するか、 「長押し」から「新しいタブを開く」を選択してください。
| ■ 数式処理ソフト「Maxima」を活用した数学学習 [Map] |
|
| ||||
|
| ||||
| [御案内] 「Maxima」(マキシマ)は,フリーの数式処理ソフトです. 有料の Mathematica や Maple に劣らないレベルの数式処理が可能であり, Linux,Windows,MacOSのみならず,Android版もあります. ここでは,数学学習での Maxima の活用法について解説します. | ||||
|
[お知らせ] スマホ(Android)版Maximaの解説本を出版しました. 計算問題やグラフの確認をするときに非常に重宝します. フリーソフトなので一度試してみてください. PC版のコマンドレファランスとしても利用できます。
| ||||
|
| ||||

| ■数学学習での活用 |
|
|
以下では,「TeXmacs」+「Maxima」の画面で基本的な使い方を解説します. |
| 確率・統計 |
| 統計に特化したソフトウェアとしては,SPSS,SAS,Rなどが有名ですが, Maximaにも統計向けのパッケージが備わっています. |
|
|
|
■いろいろな確率分布 |
いろいろな統計解析を行うには,
特定の統計量がどのような分布をするのかが重要です.
Maximaは下記のように多様な分布を扱うことができます.
世の中の多くのことは、
「正規分布」ではなく「ベキ分布」に従っているようです。
「ベキ分布:リンク集」も作成したので
参照してください。
確率分布に関するパッケージ「distrib」を読み込むと, 確率密度関数,分布関数,分布関数の逆関数,平均,分散,標準偏差,歪度係数, 尖度係数,乱数などを個々の確率分布ごとに求めることができます. 詳細は,マニュアルの「52.distrib」を参照してください. |
|
べき分布 通常の統計の教科書には書かれていないことが多いのですが, 近年,多くの分野で「べき分布」が大きく取り上げられています. これは,確率密度関数が \[\small f(x)=\frac{C}{x^{a}}\quad (x\geq b, b>0)\] の形で表される確率分布で「パレート分布」とも呼ばれます. 一般には,このようなべき乗で表される関係を「べき乗則」といいます. 重力やクーロン力のような関係にあるものもべき乗則にしたがっています. 自然界の現象のみならず, 市町村の人口やWeb上の検索ランキングなど, いろいろな分野でべき乗則にしたがう現象が指摘されており, その背後には何か共通の原理があるのではないかと研究が進められています. 「ベキ分布:リンク集」も参照してください。
[お知らせ]
「べき分布とべき乗則」についてまとめた解説
本を出版します.
べき分布の基礎から「べき分布:リンク集」で扱っている各種のテーマを,
一通りは解説できたのではないかと思っています.
「べき分布」や「べき乗則」に関心を持たれている方はご利用下さい.
(2025.11)

森北出版 (試し読み) (note), amazon, 紀伊國屋, 楽天, 丸善, Honya Club, e-hon |
|
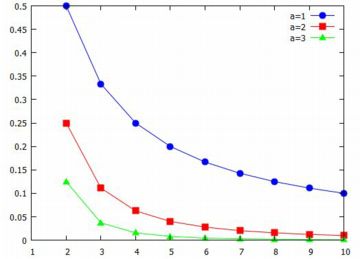
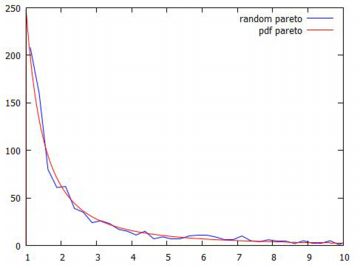
確率密度関数 べき分布の確率密度関数 \(\small f(x)={C}/{x^a}\) の分子の \(\small C\) は規格化定数と呼ばれるものです. この関数が確率密度関数であるためには, \(\small \int_b^{\infty}f(x)\,dx=1\) でなければならないので, \[\begin{align*} \small \int_b^{\infty}f(x)\,dx &\small =\bigg[\frac{C}{(-a+1)x^{a-1}}\bigg]_b^{\infty}\\ &\small =\lim_{x\to\infty}\frac{C}{(-a+1)x^{a-1}}\\ &\small \qquad -\frac{C}{(-a+1)b^{a-1}}\\ &\small =-\frac{C}{(-a+1)b^{a-1}}=1\\ &\small \qquad (a \gt 1)\\ \small \therefore\quad C&\small =(a-1)b^{a-1} \end{align*}\] したがって,\(\small a\gt 1\) のとき,確率密度関数は次のように表せます. \[\small f(x)=\frac{(a-1)b^{a-1}}{x^a}\] 簡単のため \(\small a-1\) を \(\small a\) と置き直して, \[\small f(x)=\frac{ab^a}{x^{a+1}}\] で考えます.ただし,\(\small a>0, b>0, x\geq b\) とします. この式は,次のようにも表せます. \[\small f(x)=\frac{a/b}{(x/b)^{a+1}}\] この関数を, Maximaでは「pdf_pareto(x,a,b)」により参照することができます. 以下では,簡単のため \(\small b=1\) として, \[\small f(x)=\frac{a}{x^{a+1}}\quad (a>0, x\geq 1)\] で考えることにします.「pdf_pareto(x,a,1)」を考えることになります. 以下では,パッケージ「distrib」と「descriptive」を読み込んだ上で 以上の計算を行っています.
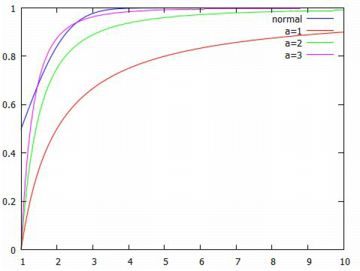
次に,累積分布関数 \(\small F(x)\) を計算してみましょう. \[\begin{align*} \small F(x) &\small =\int_{1}^{x}\frac{a}{t^{a+1}}\,dt\\ &\small =\big[-\frac1{t^a}\bigg]_{1}^{x} =1-\frac1{x^a} \end{align*}\] このように,べき分布の累積分布関数も べき関数で表されます.この関数は, 「cdf_pareto(x,a,1)」により参照することができます. |
|
|
|
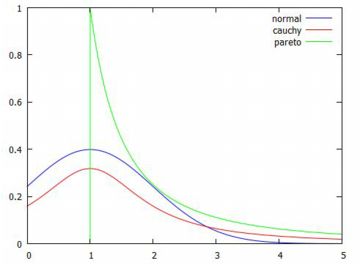
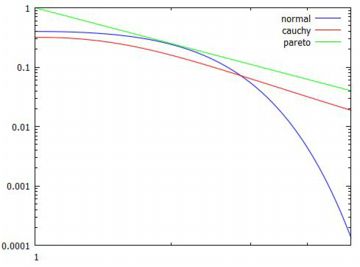
グラフの比較 この確率分布のグラフがどのようになるかを, 他の確率分布と比較してみましょう. \(\small x\geq 1\) の部分だけを考えるので, 他の分布も\(\small x=1\) が中心になるように平行移動して, 正規分布は「pdf_normal(x,1,1)」, コーシー分布は「pdf_cauchy(x,1,1)」として比較すると, \(\small a=1\) の場合は次のようになります.
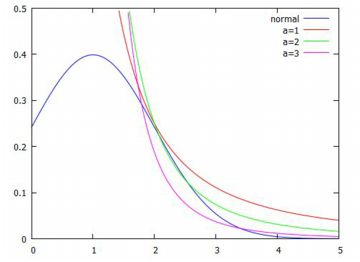
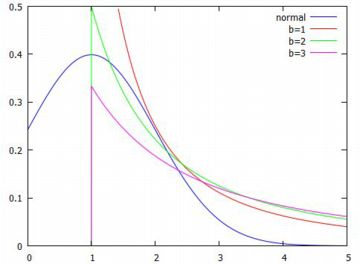
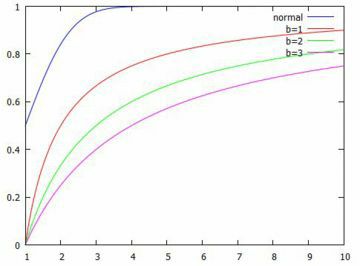
参考までに,\(\small b\) の値の違いも見ておきましょう. この値を増やすと,\(\small x\geq b\) であることからグラフは右にずれていきます. そこで,同じ箇所から始まるように平行移動して考えると次のようになり, 値が大きくなるにつれて裾が厚くなるようです.
|
|
|
|
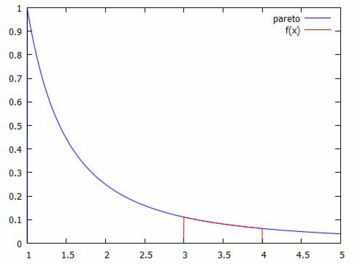
上側%点 次に,\(\small P(X\geq n)\) の値を求めてみましょう. 累積分布関数 \(\small F(x)\) は「cdf_parete(x,a,b)」で表されるので, この場合は「\(\small 1-{\rm cdf}\_{\rm pareto}(n,a,1)\)」を求めることになります.実際には, \[\small {\rm cdf}\_{\rm parete}(x,a,1)=1-\frac1{x^a}\] であるので, \[\small 1-{\rm cdf}\_{\rm parete}(x,a,1)=\frac1{x^a}\] となります.したがって,\(\small a=1\) のとき, つまり \(\small f(x)=1/x^2\) のときは, \(\small 1-F(x)=1/x\) です. 後でみるように, \(\small a=1\) のとき平均と分散は存在しません.
検定では,上側確率や下側確率が重要です.\(\small \alpha\) の 値が与えられたとき, \(\small P(X\geq x)=\alpha\) となる \(\small x\) は どのような値でしょうか.それは \(\small P(X\leq x)=1-\alpha\) でもあるので,累積分布関数の逆関数, つまり「quantile_pareto(x,a,b)」を利用すると \(\small \alpha\) を与えて \(\small x\) の値を求めることができます.
|
|
|
|
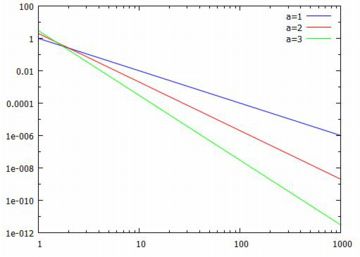
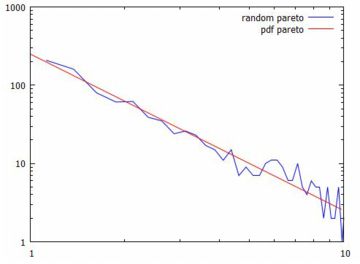
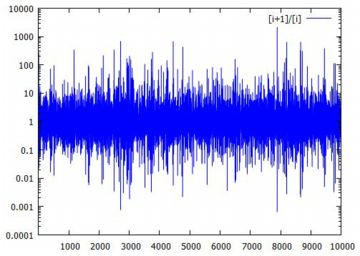
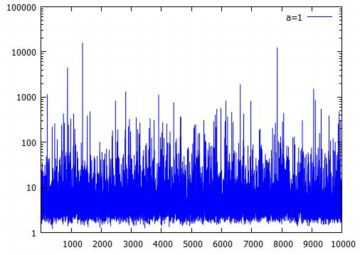
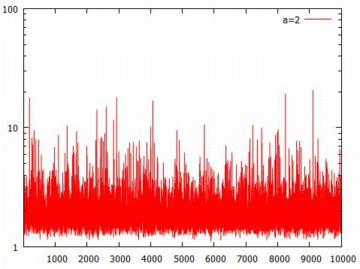
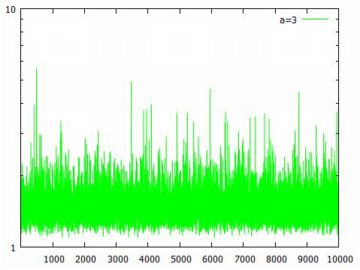
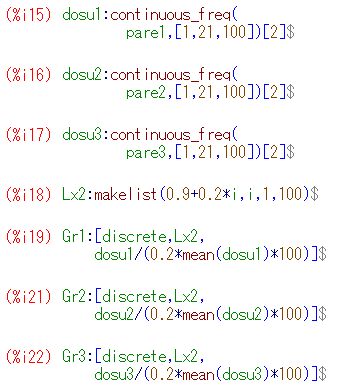
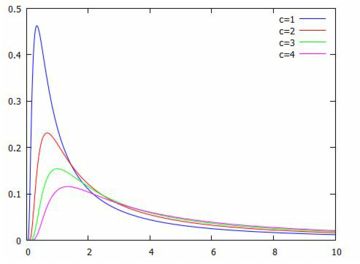
対数化変換 べき分布の確率密度関数 \(\small y=a/x^{a+1}~(a>0, x\geq 1)\) において, 両辺の対数(常用対数)をとると \[\small \log{y}=\log{a}-(a+1)\log{x}\] となります.ここで,2つの座標軸を対数軸にして \(\small Y=\log{y}, X=\log{x}\) とおくと \[\small Y=\log{a}-(a+1)X\] という1次式で表され,\(\small X, Y\) に関するグラフは直線になります. べき分布のグラフは, 急激に減少した後の詳細が把握しにくいので, 対数を取って考えることが多いようです. 確率密度関数を \(\small f(x)=ax^{-(a+1)}\) の形で表したときの 指数部分が直線の傾きになっています. また,両対数グラフが直線 \(\small Y=\log{C}+\beta X\) となる場合は, \[\small \log{y}=\log{C}+\log{x^{\beta}} =\log{Cx^{\beta}}\] となることから, \(\small y=Cx^{\beta}\) というベキ関数になることも分かります. 以下は,\(\small a=1,2,3\) の場合のグラフを両対数グラフで描画したものです. \(\small a\) の値が大きくなるにつれ下降が急になることが分かります.
(%i15)では,度数分布をそのまま離散グラフとして表示させるため, \(\small x\) 軸側の分点リストを作成しています. (%i16)では,離散グラフとパレート分布の確率密度関数を表示させています. 縦のスケールを揃えるため,密度関数には分割幅と総度数を掛けています. 座標軸を対数軸とするには,「logx」「logy」を指定するだけです.
このように,急激に減少するものの,そのままダラダラと度数が途切れなく 続く分布が「べき分布」(パレート分布)です. 両座標軸を対数軸に取ると直線的になるのが特徴です. このような特徴をもつ分布は身の周りに多数散見されることから, 世の中で重要な分布は「正規分布ではなくてべき分布なのではないか?」 とも言われているようです.後で述べる 「80:20の法則」や 「ジップの法則」も, 要するに「べき分布」です. |
|
|
|
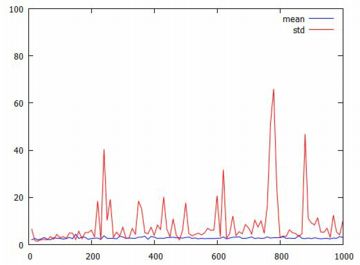
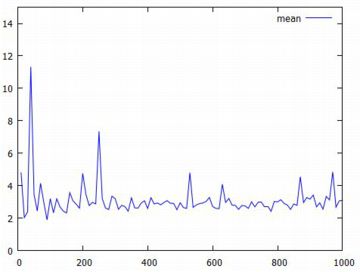
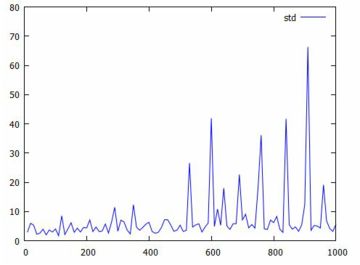
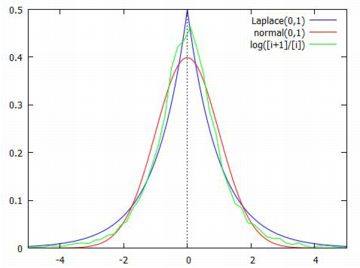
平均と分散 べき分布の平均と分散を計算してみましょう. 確率密度関数を \(\small f(x)=a/x^{a+1}~(a>0, x\geq 1)\) とすると, 次のように計算されます. \[\begin{align*} \small \int_{1}^{\infty}xf(x)\,dx &\small =\int_{1}^{\infty}\frac{ax}{x^{a+1}}\,dx\\ &\small =\int_{1}^{\infty}ax^{-a}\,dx\\ &\small =\big[\frac1{1-a}ax^{1-a}\big]_1^{\infty}\\ &\small =\lim_{x\to\infty}\frac{a}{(1-a)x^{a-1}}\\ &\small \quad -\frac{a}{1-a}\\ &\small =\frac{a}{a-1}\quad (a\gt 1 のとき)\\ \small \therefore\quad E(X)&=\small \frac{a}{a-1}\quad (a\gt 1) \end{align*}\] 上の計算からも分かるように,この積分は \(\small 0\lt a\leq 1\) のときは発散してしまいます. \(\small a\gt 1\) であれば平均が存在します. \[\begin{align*}\small \small \int_{1}^{\infty}x^2f(x)\,dx &\small =\int_{1}^{\infty}\frac{ax^2}{x^{a+1}}\,dx\\ &\small =\int_{1}^{\infty}ax^{1-a}\,dx\\ &\small =\big[\frac{a}{2-a}x^{2-a}\big]_1^{\infty}\\ &\small =\lim_{x\to\infty}\frac{a}{(2-a)x^{a-2}}\\ &\small \quad -\frac{a}{2-a}\\ &\small =\frac{a}{a-2}\quad (a>2 のとき)\\ \small \therefore\quad V(X)&\small =E(X^2)-E(X)^2\\ &\small =\frac{a}{a-2}-\left(\frac{a}{a-1}\right)^2\\ &\small =\frac{a}{(a-1)^2(a-2)} \end{align*}\] ここでも,\(\small a\leq 2\) であれば分散は存在しません. 同様に計算していくと,\(\small a\leq 3\) のときは歪度が, \(\small a\leq 4\) のときは尖度が存在しません. 次に,「分散が存在しない」ということを, コーシー分布のときと同様の手法で確認してみましょう. 標本分散だと値が大きくなるので,標本標準偏差で確認します.
以下は,標本平均と標本標準偏差の変化を個別にみたものです. 上段は標本平均の変化,下段は標本標準偏差の変化です. いずれも,上図とは異なる乱数によるものです.
標本標準偏差が大きな値を取るとき, 具体的にはどのような値になっているのでしょうか. 試みに「plist2(10)」により10個の成分を持つリストを発生させ, 標本標準偏差が大きな値になるまで何度か試したところ, 次の例が生成されました.
|
|
|
|
80:20の法則 パレート分布は,イタリアのヴィルフレド・パレートにより提唱されたものです. 経済社会における所得分布を分析して, 2割の高額所得者のもとに社会全体の8割の富が集中して, 残りの2割の富が8割の低所得者に配分されるという「パレートの法則」を 見いだしました.この法則は「80:20の法則」と呼ばれることもあり, 経済学のみならず自然現象や社会現象などの様々な事例にあてはまるとされます. Wikipediaでは, 下記の例が紹介されています.
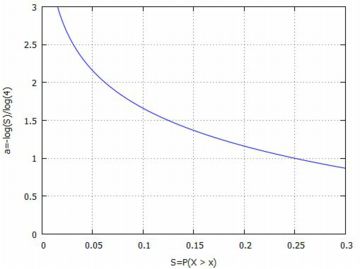
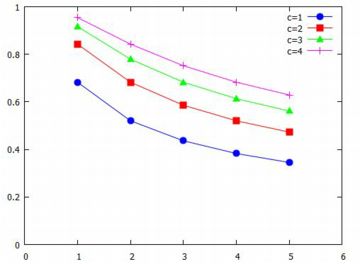
富が \(\small x\) 以上である人の割合 \(\small S\) は 既に計算済みの式から \[\small S=1-P(X\lt x)=\frac{1}{x^a}\] であり,その人達の富は, \[\small \int_x^{\infty} tf(t)\,dt=\frac{a}{(a-1)x^{a-1}}\] で表されます.一方,富全体は,\(\small a>1\) の場合は \[\small \int_1^{\infty} tf(t)\,dt=\frac{a}{a-1}\] となるので,富全体の中で,富が \(\small x\) 以上の人達の富の 占める割合 \(\small T\) は \(\small T=1/x^{a-1}\) で表されます. つまり,富が \(\small x\) 以上である人達の割合 \(\small S\) と, その人達の富が全体の富の中で占める割合 \(\small T\) の間には \[\small T=S^{\frac{a-1}{a}}\] という関係があることになります. したがって,富の80%を20%の人達が占めているという関係は, \[\small T:S=80:20\] ということから \[\small S^{\frac{a-1}{a}}:S=80:20\] これより \(\small 4=S^{-\frac1{a}}\) が得られ,両辺の対数をとることにより \[\small a=-\frac{\log{S}}{\log{4}}=-\frac12\log_2{S}\] という関係が得られます. 下図は,\(\small S=P(X\geq x)\) の値と指数 \(\small a\) との関係を 図示したものです.
|
|
|
|
ジップの法則 ベキ分布の特別な場合に「ジップ(Zipf)の法則」と呼ばれるものがあります. これは,いろいろな現象において, 「ある事象 \(\small A\) の規模と事象 \(\small A\) の順位の積は一定である」 という経験則です. George K. Zipfは言語学者で,小説「ユリシーズ」で使われた 260,430単語に 現れる29,899単語の出現頻度を調べ, 単語の出現回数と出現順位の積が一定であることを見いだしました. つまり,ある単語が \(\small N\) 回現れ, その単語の出現順位が \(\small n\) 番目とすると \(\small Nn=C~(定数)\) であること, つまり,\(\small N={C}/{n}\) という関係があることを見いだしました. ある事象の総量と順位との関係では,他にも多数のものが ジップの法則にしたがうとされています. Wikipediaでは, 次のような例が挙げられています. ベキ分布の実例も参照してください.
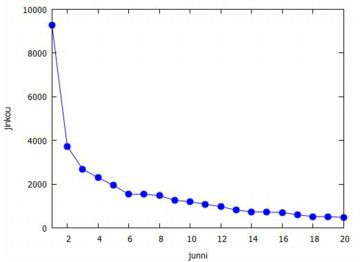
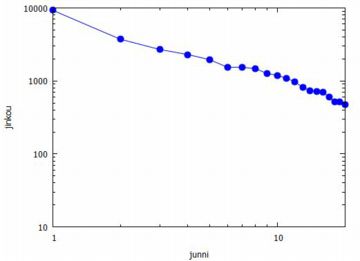
この法則は,一見するとべき分布 \(\small {C}/{x^a}\) の \(\small a=1\) の場合のように見えるのですが, 以下にみるように,べき分布 \(\small {C}/{x^2}\) の 累積分布関数として捉えることができるようです. 最初に, ランキングサイトをもとに, 平成27年の国勢調査による県庁所在地47都市の上位20位までの人口と 順位のグラフを以下に示します. 下図は,上位20都市の人口と順位のグラフ,そして両対数グラフです. 縦軸の人口の単位は「千人」としています.
次に,[丸田]をもとに, 人口 \(\small x\) と順位 \(\small R\) の関係をみてみましょう. まず,上図にあるように, 両対数グラフで考えると,人口と順位との間には直線の関係が見られるます. したがって,対数化変換の箇所で見たように, この2つの変量の間には \[\small x=aR^{-\beta}~(a:正の定数)\] という関係があります. この式より, \[\small R=a^{\frac1{\beta}}x^{-\frac1{\beta}}\] が得られます. ここで,都市総数を \(\small N\) として,\(\small r=R/N\) とおくと, \(\small r\) は全都市の中での順位比率を表します.このとき, \(\small R=rN\) より,上式は \[r=\frac{A}{N}\cdot x^{-\frac1{\beta}}\quad (A=a^{\frac1{\beta}})\] となります.\(\small r\) の定め方から \(\small 0\leq r\leq 1\) であり,この値が小さいほど人口が多いことを, 値が 1 に近いほど人口が少ないことを表します. つまり, 都市の人口を表す確率変数を \(\small X\) とすると, \(\small r\) の値は \[\small P(X\gt x)=r\] を意味する値として捉えることができます. したがって,その逆を考えると, \[\begin{align*} \small P(X\leq x) &\small =1-r\\ &\small =1-\frac{A}{N}\cdot x^{-\frac1{\beta}} \end{align*}\] となります.これは,累積分布関数です. この関数を \(\small F(x)\) とおいて微分することにより, 確率密度関数 \(\small f(x)\) は \[\begin{align*} \small f(x) &\small =F'(x)\\ &\small =\frac{A}{N\beta}\cdot x^{-\frac1{\beta}-1}\\ &\small =\frac{A/(N\beta)}{x^{\frac1{\beta}+1}} \end{align*}\] となります.\(\small \beta=1\) の場合がジップの法則です. |
|
|
|
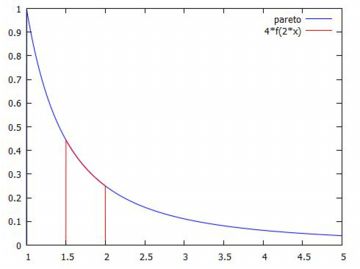
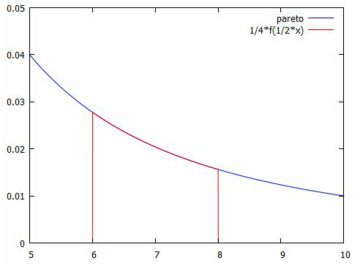
分布の相似性 べき分布は「自己相似性」を持つとされます. それは,スケール変換をしても同じべき乗になることを指します. 実際,べき分布の確率密度関数を \(\small f(x)\) とすると, \[\small f(x)=\frac{a}{x^{a+1}}\] です.今,\(\small x\) を \(\small c\) 倍すると, \[\small f(cx)=\frac{a}{(cx)^{a+1}} =\frac{a/c^{a+1}}{x^{a+1}}\] となり,同じベキを持ちます. この式をグラフでみると,横軸を \(\small c\) 倍したときは, 縦軸を \(\small c^{a+1}\) 倍すると同じグラフになることを示します.
また,このような性質を持つ関数はベキ関数に限られることを導くことが
できます.以下は,「須鎗弘樹:複雑系のための基礎数理(牧野書店),p10」を
もとにしたものです.
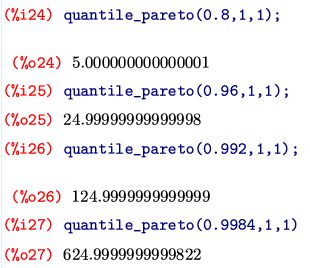
この自己相似性を別な角度から見てみましょう. \(\small a=1\) の場合に「80:20の法則」を考えます. p分位数のコマンド「quantile_pareto(p,1,1)」を利用すると, 下図にあるように [1,5] の範囲に全体の 4/5 が含まれることが分かります. では,残りの \(\small [5,\infty)\) のうちの 80% の箇所はどこでしょうか. それは,全体では \(\small 0.8+0.2\cdot 0.8=0.96\) の箇所なので,同じコマンドを利用すると [5,25] の範囲です. 同様にすると,残りの \(\small [25,\infty)\) のうちの 80%の箇所は,全体では \(\small 0.96+0.04\cdot 0.8=0.992\) の箇所なので [25,125], その残りの \(\small [125,\infty)\) のうちの 80% を占めるのは, 全体では \(\small 0.992+0.008\cdot 0.8=0.9984\) の箇所なので [125,625] の範囲です.範囲が,いずれも 5 のべき乗になっています.
同じことを \(\small f(x)=a/x^{a+1}\) で考え, \[\small \int_1^{c}f(x)\,dx=p\] とします.\(\small p\) の値は,実際には \[\begin{align*} \small p &\small =\int_1^{c}\frac{a}{x^{a+1}}\,dx\\ &\small =\bigg[-\frac1{x^a}\bigg]_1^c\\ &\small =1-\frac1{c^a}\\ \small \therefore\quad \frac1{c^a} &\small =1-p \end{align*}\] ここで, 残りの \(\small [c,\infty)\) の箇所で同じ割合 \(\small p\) を占める部分は 全体では \(\small (1-p)p=p/c^a\) です. この値は,\(\small x/c=t\) と変数変換して 次の積分を計算しても得られます. \[\begin{align*} \small \int_1^{c}f(ct)\,cdt &\small =\int_1^c\frac{a}{(ct)^{a+1}}\,cdt\\ &\small =\frac1{c^a}\int_1^c\frac{a}{t^{a+1}}\,dt\\ &\small =\frac{p}{c^a} \end{align*}\] 他の箇所でも同様であり, スケール変換すると同じ積分範囲で計算することができます. このように,部分が全体と同じような性質を持つことから, この性質は「スケールフリー」や「フラクタル性」と呼ばれます. |
|
|
|
平均の分布 べき分布では,指数の値によっては平均や分散を持たない場合があります. 中心極限定理は 平均や分散が存在するような確率分布に関する定理です. それらが存在しない確率分布では,標本平均はどのような分布になるのでしょうか. ここで,ベキ分布で \(\small a=1, b=1\) の場合の 乱数「random_pareto(1,1)」を利用して, 標本平均の分布がどのようになるかを確かめてみましょう. この分布は,平均も分散も存在しません. 平均の存在しない確率分布で乱数を発生させると, コーシー分布の箇所でみたように 標本数を幾ら増やしても標本平均の値は安定しません. その振れ幅は非常に大きなものになります. Maximaのバージョンの古い「TeXmacs+Maxima」では 度数分布の作成で支障をきたすので, 以下ではwxMaximaを利用します. 行番号はリセットして「distrib」と「decriptive」のパッケージを 読み込んでいます.
以上の準備のもとで, グラフは(%i12)により下図のようになります.
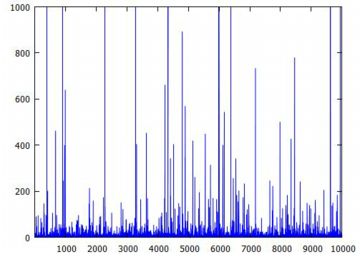
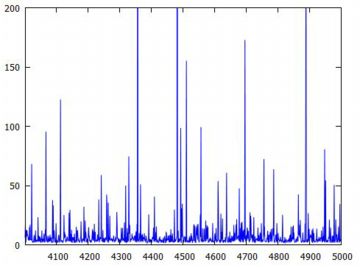
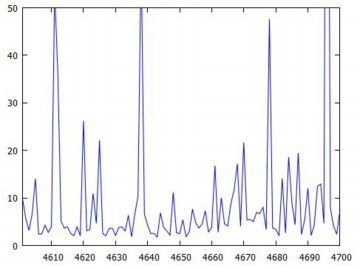
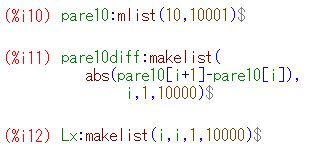
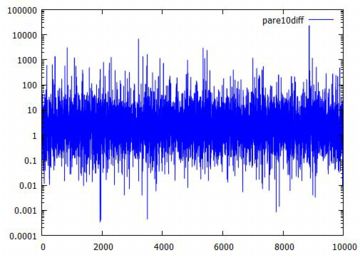
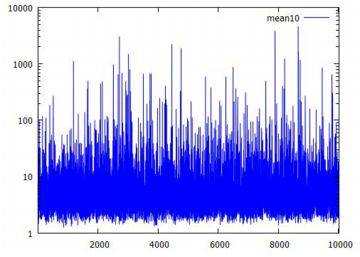
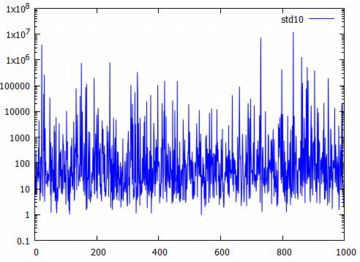
下記は,同様にして乱数の10個平均のリスト「pare10」を作成して固定したとき, その生データをみたものです.横軸は何回目の標本平均であるかを表します. 上から順に,10個平均の1万個のデータ,そのうちの4001〜5000番目のデータ, そして4601〜4700番目のデータです. 縦のサイズは調整しましたが,どの場面でみても 同じような上下動が繰り返されています. 分布としての平均や分散が存在しないので, 標本平均を何回取ってもどのような値になりそうなのか「全く分からない」ということです. おまけに,1万個のデータを見れば分かるように, 10個平均の値が1000を超えることが何度かあります. ときどき,「とんでもないことが起きることがある」ということです.
|
|
|
|
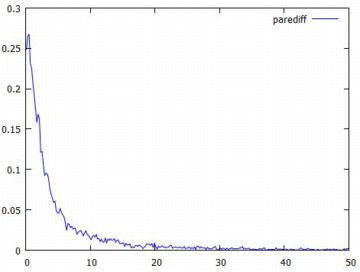
標本平均の差の変化 前項で,標本平均を求める度に値が大きく変動している様子を見ました. その変動幅はどの程度のものなのかを調べてみましょう.
以上のもとでグラフを描くと次のようになります.
|
|
|
|
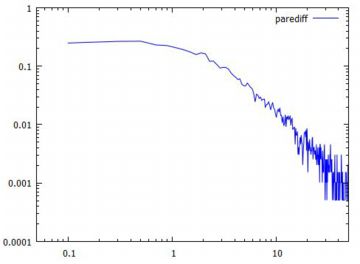
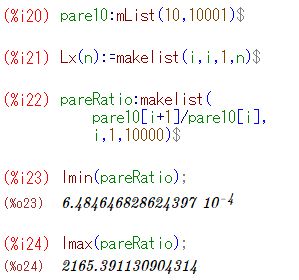
標本平均の比の変化 前項で,10個平均の差の絶対値がべき分布になっているのを見ました. ここでは,隣同士の比がどのように変化するかを眺めてみましょう. 最初に,(%i20)により10個平均のリストを作り直します.
下図は,一つ前の標本平均との比のグラフです.これも対数軸にしています. 激しく振動していることが分かります.
|
|
|
|
分散の有無による比較 今度は,分散の存在の有無により 標本平均の分布がどのように異なるかをみてみましょう. 「平均と分散」の箇所でみたように, ベキ分布 \[\small f(x)=\frac{a}{x^{a+1}}\] は,\(\small a=1\) のときは平均と分散が存在しません. \(\small a=2\) のとき平均は \(\small E(X)=2\) ですが 分散は存在しません.\(\small a=3\) のときは 平均は \(\small E(X)=\frac32\) , 分散は \(\small V(X)=\frac34\) になります.
以上のもとで, \(\small a=1\) の場合の標本平均の分布の様子を描画したのが下図です.
下図は,\(\small a=2\) の場合です.
下図は,\(\small a=3\) の場合です.
今度は,以上のリストのヒストグラムを見てみましょう.
以上のもとで,この区間のヒストグラムは下図のようになります. 両対数軸のグラフも示しました.
以上の例から,平均や分散が存在しないような確率分布では 標本平均は大きく変動するものの, そのヒストグラムは正規分布とは異なる何か別の確率分布に したがうのではないかと考えられます. それが,別ページで述べる「安定分布」です. 正規分布もコーシー分布も安定分布です. そして,ベキ分布 \(\small a/x^{a+1}\) にしたがう確率変数の和の分布は, 標本数を大きくしていくと,同じ指数 \(\small a\) を持つ 安定分布に収束していくことが証明されています (参照,p.12(19)). そのことを確かめるには安定分布を理解する必要がありますが, 安定分布の確率密度関数を初等関数で表すことができるのは, 正規分布,コーシー分布,そして次の項目にあるレビ分布に限られます. 他の場合は数値的に調べるしかありません. Maximaには「安定分布」に関するパッケージはないので, 以上のことを確かめるため, 安定分布に関するパッケージを持つ「R」を使用することにします. この件に関する詳細は「こちら」を参照してください. |
|
|
|
べき分布の実例 ここでは,ベキ分布・自己相似性・べき乗則を持つ 実例について詳細に述べている記事や論文を集めてみました. すでに「パレートの法則」や「ジップの法則」の箇所で 紹介した内容もありますが,具体的なグラフや解説が加えられており, 両対数軸で考えると右下がりか右上がりの直線上に乗っています.
|
|
|
|
レビ分布
確率密度関数
諸関数の定義
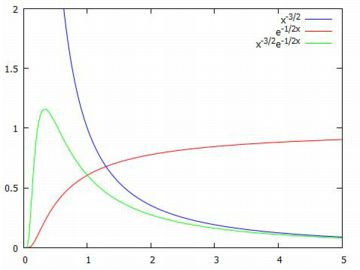
次に,簡単のため \(\small \gamma=1, \delta=0\) の場合を考え, Maximaの書式に合わせて \[\small {\rm pdf\_levi}(x)=\frac{1}{\sqrt{2\pi}} x^{-{\frac32}}e^{-\frac{1}{2x}}\] が確率密度関数の場合を考えます. この分布にしたがう乱数を発生させるには, 累積分布関数の逆関数 を考える必要があります. レビ分布の累積分布関数は, 下記により計算することができます. \[\begin{align*} \small {\rm cdf\_}&\small {\rm levi}(x)=P(X\leq x)\\ &\small =\int_{0}^{x}{\rm pdf\_levi}(t)\,dt\\ &\small =\frac1{\sqrt{2\pi}} \int_{0}^{x}t^{-{\frac32}}e^{-\frac{1}{2t}}\,dt\\ &\small =1-\frac1{\sqrt{2\pi}} \int_{x}^{\infty}t^{-{\frac32}}e^{-\frac{1}{2t}}\,dt\\ \end{align*}\] しかしながら,この積分は初等積分可能ではありません. 右辺の第2項は,フーリエ解析の箇所で現れた 第ニ種不完全ガンマ関数 に似ています.第ニ種不完全ガンマ関数は, \[\small \Gamma(a,x)=\int_{x}^{\infty}t^{a-1}e^{-t}\,dt\] で定義される関数です. ここで,形を揃えるために \(\small 1/2t=s\) として置換積分を行うと, \(\small t=1/2s,~dt=-1/2s^2\) であることから, 次のように変形されます. \[\begin{align*} \small {\rm cdf\_}&\small {\rm levi}(x)\\ &\small =1+\frac1{\sqrt{\pi}} \int_{\frac1{2x}}^{0} s^{-\frac12}e^{-s}\,ds\\ &\small =1-\frac1{\sqrt{\pi}} \int_{0}^{\frac1{2x}} s^{-\frac12}e^{-s}\,ds \end{align*}\] さらに \(\small s^{\frac12}=u\) とおくと, \(\small s=u^2,~ds=2udu\) であることから, \[\begin{align*} \small {\rm cdf\_}&\small {\rm levi}(x)\\ &\small =1-\frac2{\sqrt{\pi}} \int_0^{\frac1{\sqrt{2x}}} e^{-u^2}\,du\quad (1) \end{align*}\] となります.第2項は誤差関数です. 誤差関数は \[\small {\rm erf}(x)=\frac2{\sqrt{\pi}}\int_{0}^{x}e^{-t^2}\,dt\] で定義されるので,累積確率分布関数は \[\begin{align*} \small {\rm cdf\_}&\small {\rm levi}(x)\\ &\small =1-{\rm erf}\left(\frac1{\sqrt{2x}}\right) \end{align*}\] と表されます. 乱数を発生させるには,この関数の逆関数を求めなければなりません. 上式から \[\small 1-{\rm erf}\left(\frac1{\sqrt{2y}}\right)=x\] とすると, \[\begin{gather*} \small {\rm erf}\left(\frac1{\sqrt{2y}}\right)=1-x\\ \small \frac1{\sqrt{2y}}={\rm erf}^{-1}(1-x)\\ \small \therefore\quad y=\frac1{2\left\{{\rm erf}^{-1}(1-x)\right\}^2} \end{gather*}\] したがって,レビ分布の累積確率分布関数の逆関数は 次の式で表されます. \[\begin{align*} \small {\rm quant\_}&{\rm levi}(x)\\ &\small =\frac1{2\left\{{\rm erf}^{-1}(1-x)\right\}^2} \end{align*}\] なお,「quantile_levi」とすべきところを簡略化しています. 誤差関数に対して \(\small {\rm erfc}(x)=1-{\rm erf}(x)\) を 相補誤差関数といいます. この関数を利用すると, \[\small {\rm quant\_levi}(x)=\frac1{2\left\{{\rm erfc}^{-1}(x)\right\}^2}\] と表すこともできます. 以下では \(\small {\rm erf}^{-1}(1-x)\) を利用した式で考えます. したがって,レビ分布にしたがう乱数は, \[\begin{align*} &\small {\rm random}\_{\rm levi}(1,0)\\ &\small ={\rm quant}\_{\rm levi}({\rm random}(1.0)) \end{align*}\] により発生させることができます. |
|
|
|
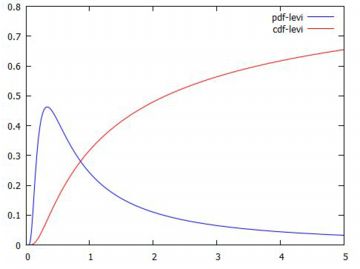
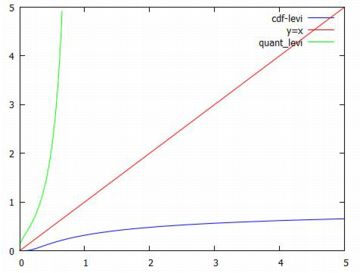
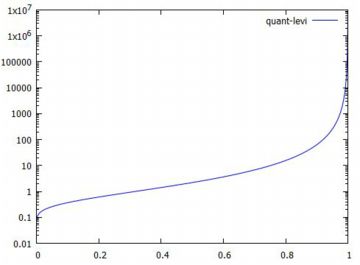
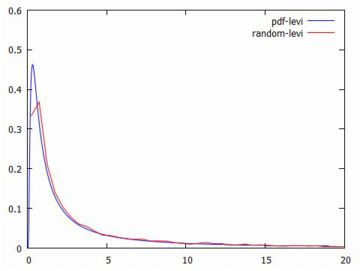
グラフの確認 次に,以上で定義した関数のグラフを確認してみましょう.
グラフは,下図のようになります.
|
|
|
|
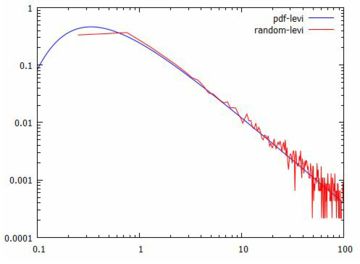
乱数の分布 以上の準備のもとで,レビ分布にしたがう標本の標本平均の分布の様子を 調べてみましょう.
以上をもとにすると下図のようなグラフが得られます. 刻み幅を 0.5 にしているので最初の部分はちょっと切れますが, レビ分布の確率密度曲線と重なっていることが分かります.
|
|
|
|
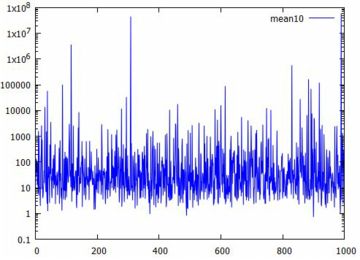
平均と分散 レビ分布は,平均も分散も存在しません. 実際の計算で確かめてみましょう. \[\begin{align*} \small E(X) &\small =\int_{0}^{\infty}x\cdot{\rm pdf}\_{\rm levi}(x)\,dx\\ &\small =\int_{0}^{\infty}x\cdot\frac1{\sqrt{2\pi}} \frac1{x^{\frac32}}e^{-\frac1{2x}}\,dx\\ &\small =\int_{0}^{\infty}\frac1{\sqrt{2\pi}}x^{-\frac12}e^{-\frac1{2x}}\,dx\\ &\small \gt \int_{1}^{\infty}\frac1{\sqrt{2\pi}}x^{-\frac12}e^{-\frac12}\,dx\\ &\small =\frac1{\sqrt{2\pi e}}\int_{1}^{\infty}x^{-\frac12}\,dx\\ &\small =\frac1{\sqrt{2\pi e}}\big[2\sqrt{x}\big]_1^{\infty}=\infty \end{align*}\] ここでは,\(\small [1,\infty)\) では \(\small 1/2x\lt 1/2\) より \(\small -1/2x\gt -1/2\) であることを利用しています. したがって,平均が存在しないので,分散も存在しません. 次に,実際の標本平均を調べて,「平均も分散も存在しない」ということを 確かめてみましょう.
\(\small 6.698\cdot 10^3, 5.162, 1.333, 486.5, 0.2898,\) \(\small 0.2355, 24.0, 2.712\cdot 10^3, 10.82, 2.99\) |
|
|
|
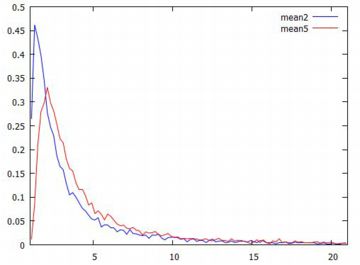
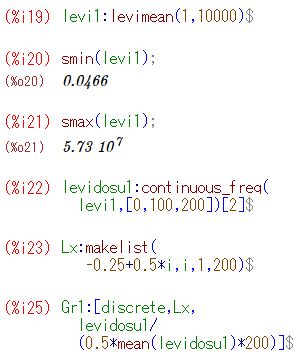
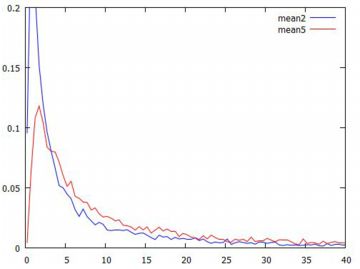
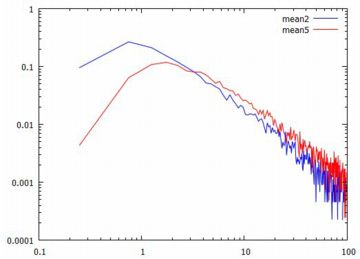
平均の分布 標本平均の値が大きく振れていることは分かりましたが, その値はどのような分布をしているのか2個平均と5個平均の場合で調べてみましょう. 他の分布の場合と同様に平均を要素とするリストを作成するには, 5個平均の場合は5万回の乱数を発生させることになります. 1万回でもエラーが生じます. 5回連続でエラーが出ないことは考えにくいので, 最初に,エラーの生じない1万要素のリストを生成しておくことにします. 1万個であれば,数回試せば生成されます.
(%i43)(%i44)では,[0,100] を 200 等分した度数分布を作成し, (%i56)(%i57)でグラフを描くときの書式を定めています. 番号が飛んでいるのは,\(\small y\) 軸に指定するリスト名を 間違えていたことに気づいて修正したためです. \(\small x\) 軸の分点リストは,すでに(%i23)で作成済みです. 以上をもとにグラフを描くと,次のようになります.
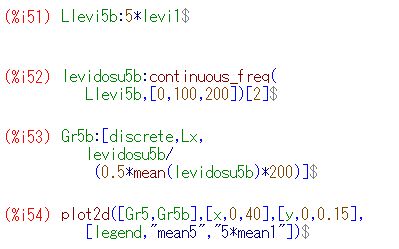
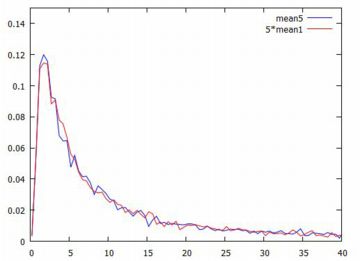
確率分布の範疇に「安定分布」 と呼ばれるものがあり,レビ分布は安定分布です. そして,安定分布の性質[15]によれば, レビ分布の特性指数は \(\small \alpha=1/2\) であるので \(\small n^{1/\alpha}=n^2\) となり, \[\small X_1+X_2+\cdots+X_n\overset{d}{=}n^2X\] となるはずなので,標本平均の分布については \[\small \frac1{n}(X_1+X_2+\cdots+X_n)\overset{d}{=}nX\] になるはずです. そこで,5個平均の分布について,このことを確かめてみましょう. 下記は,後でやり直しているので行番号がずれています.
|
|
|