統計処理ソフト「R」を活用して統計解析を究めよう!
(注) MathJaxを使用しているので、 スマホでは表示に時間がかかることがあります。
モバイル利用(Android)でのメニュー選択は、 SiteMapを利用するか、 「長押し」から「新しいタブを開く」を選択してください。
| ■ 「R」に関する備忘録 [Map] |
| [御案内] フリーの本格的な統計処理ソフトに「R」があります. ここでは,「R」のパッケージを取り扱うに至るまでの 「R」の利用法について備忘録的に取りまとめました. 「R Studio」は使用していません. |
|
|
|
|
| 「R」のパッケージ |
|
|
|
パッケージのインストール 「R」では,標準で備わっている機能の他に, パッケージを読み込ませることでいろいろな機能を利用することができます. 標準で登録されているパッケージは「library()」とすると表示されます.
上記の「パッケージの読み込み」で表示されなくても, 「R」で利用できるパッケージとしては膨大な量のパッケージがあります. どのようなパッケージを利用できるかは, 上部メニューの「パッケージ」から「パッケージのインストール」を選択します. 最初に,ダウンロードできるサーバーのリストが表示されるので, 希望するサーバーを選択します. 普通に「Japan(Tokyo)[https]」を選択すればよいでしょう. そのサーバーに接続するには多少の時間がかかるので, 10秒前後はじっと待ちます.接続すると, ダウンロード可能なパッケージの膨大なリストが表示されるので, そこからパッケージを選択します. なお,当然ながら, 自分が必要とする機能を持つパッケージはどのようなパッケージであるかは, 事前に調べていることが前提となります.
そのパッケージは自動的に展開されてチェックサムも行われ, 「R」の作業フォルダーに保存されます. その作業フォルダーには「win-library」というフォルダーがあり, その下部フォルダーにバージョン別のフォルダーがあります. 使用している「R」のバージョンは「3.6.2」なので「3.6」の フォルダーに進むと読み込まれたパッケージ別のフォルダーがあります. そこで,「Pareto」のフォルダーに進むと「doc」フォルダーがあり, そこに「Pareto」パッケージの解説が収められています. つまり,パッケージにもよると思われますが,「Pareto」パッケージの場合の 解説は, [Rの作業フォルダー]>[win-library]>[3.6]>[Pareto]>[doc] の箇所にある「Pareto.html」です. 下図は,その冒頭部分です.日付が「2020-02-13」となっているので, 最近更新されたドキュメントであることが分かります (この文面は「2020-03-22」に書いています).
|
|
|
|
ベキ分布(パレート分布) [script] 以下は,「Pareto.html」をもとに, このパッケージに登録されている関数のうち,下記の関数の使い方についての解説です. |
|
|
|
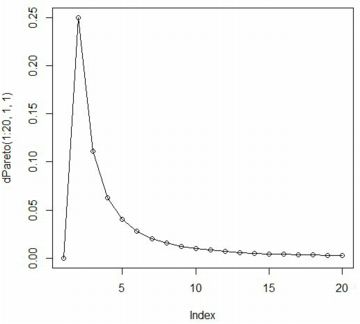
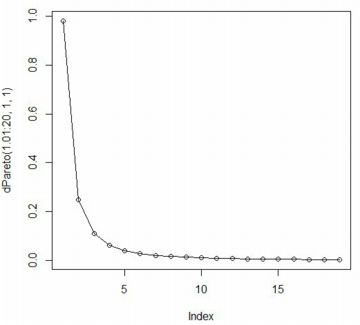
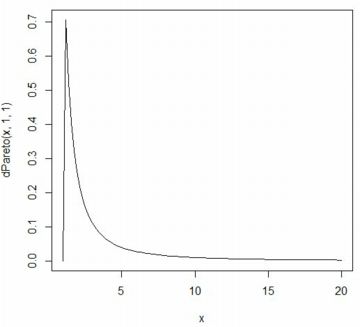
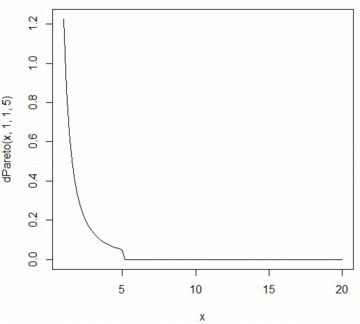
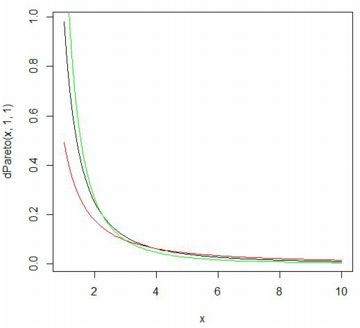
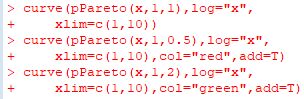
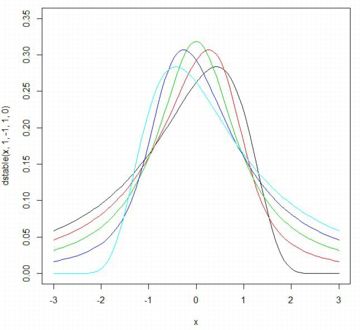
■確率密度関数(dPareto) ベキ分布(パレート分布) Pareto(t,α) の累積分布関数 \(\small F_{t,\alpha}(x)\) は, 次の式で表されます. \[\small F_{t,\alpha}=\begin{cases} \quad 0 & (x\leq t)\\ \displaystyle 1-\left(\frac{t}{x}\right)^{\alpha}& (x>t) \end{cases} \] これを微分すれば確率密度関数が得られます. \[\small \frac{d}{dx}F_{t,\alpha}(x) =\begin{cases} \quad 0 & (x\leq t)\\ \displaystyle \frac{\alpha t^{\alpha}}{x^{\alpha+1}} & (x>t) \end{cases}\] 「パレート分布」といえば,通常は上記の関数で定義される確率分布を指します. さらに専門的になると,この分布は「パレートI型」,「ヨーロピアンパレート」, あるいは「1パラメータパレート」とも呼ばれるようですが, 以後,本サイトでは「ベキ分布」と呼ぶことにします. また,「Pareto」パッケージをインストールして 「library(Pareto)」を実行済みとします. 「R」での関数名は, 確率密度関数は「dPareto」,累積分布関数は「pPareto」です. Maximaでの確率密度関数は \(\small ab^{a}/x^{a+1}~(x\geq b)\) で考えて主に \(\small b=1\) の場合を扱ったので, ここでも \(\small t=1\) の場合を考えます. 「dPareto」の書式は 「dPareto(x, t, \(\small \alpha\), truncation)」です. 「truncation」は省略可能で, デフォルトでは「truncation=NULL」になっている. 「truncation=s」とすると,\(\small t\lt x\le s\) の部分のグラフが描画され, \(\small x\gt s\) のときは「0」となります. また,「x」に点列を指定するベクトルを与えると, 「plot」で描画することができます. なお,開始点がMaximaでは \(\small x\geq b\) ですが, 「R」では \(\small x>t\) であるので注意が必要です. 範囲を \(\small x\geq t\) で指定すると,値が「0」からのグラフとなります.
plot(dPareto(1:20,1,1),type="o")
plot(dPareto(1.01:20,1,1),type="o")
curve(dPareto(x,1,1),xlim=c(1,20))
curve(dPareto(x,1,1,5),xlim=c(1.01,20))
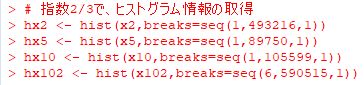
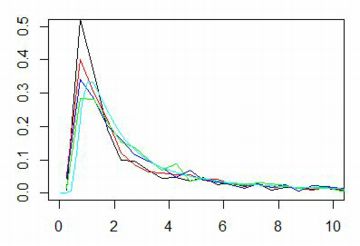
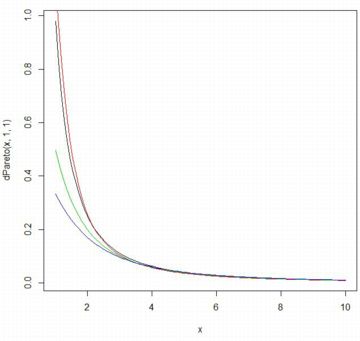
以下では,指数 \(\small \alpha\) の違いをみるため,
\(\small \alpha=0.5(赤), 1(黒), 1.5(緑)\) の場合のグラフです.
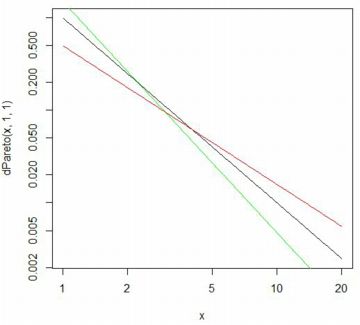
以下は,同じグラフで縦軸と横軸を対数軸としたものです.
ベキ分布は,両対数グラフでは直線になるのが特徴です.
|
|
|
|
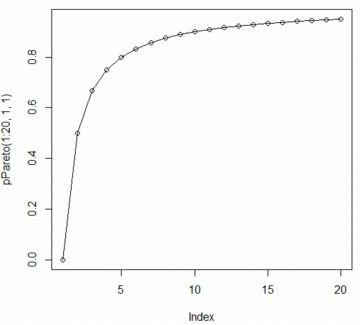
■累積分布関数(pPareto) ベキ分布の累積分布関数 \[\small F_{t,\alpha}(x) =\begin{cases} \quad 0 & (x\leq t)\\ \displaystyle 1-\left(\frac{t}{x}\right)^{\alpha}& (x>t) \end{cases}\] の「R」での名称は「pPareto」であり,書式は 「pPareto(x, t, \(\small \alpha\), truncation)」です. 使い方は「dPareto」と同様です. 累積分布関数の初期値は「0」であるので, 端点を気にする必要はありません.
plot(pPareto(1:20,1,1),type="o")
以下は,指数 \(\small \alpha\) の違いをみるため,
\(\small \alpha=0.5(赤), 1(黒), 2(緑)\) の場合のグラフです.
横軸を対数軸としました.
|
|
|
|
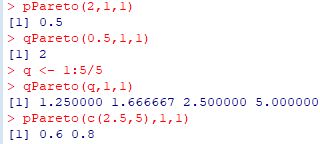
■分位関数(qPareto) 分位関数「qPareto」は,累積分布関数「pPareto」の逆関数です. つまり,「\(\small {\rm qPareto}\,(q,t,\alpha)=x\)」とすると, これは「\(\small {\rm pPareto}\,(x,t,\alpha)=q\)」,すなわち \(\small X\) を Pareto(\(\small t,\alpha\)) にしたがう確率変数とするとき, \(\small {\rm P}(X\le x)=q\) ということです.
下図は,qPareto(x,1,1)のグラフです. 縦軸を対数軸としています.
curve(qPareto(x,1,1),xlim=c(0,1),log="y") |
|
|
|
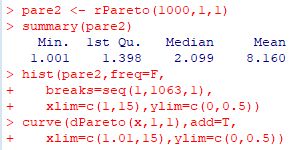
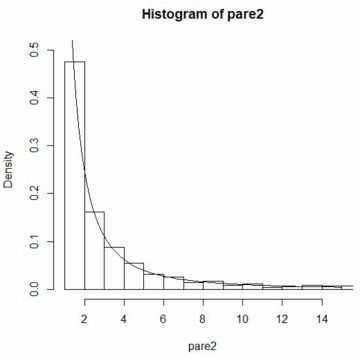
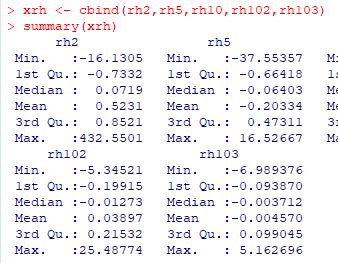
■乱数(rPareto) 「rPareto」を利用すると, ベキ分布 Pareto(\(\small t,\alpha\)) にしたがう 乱数を発生させることができます.
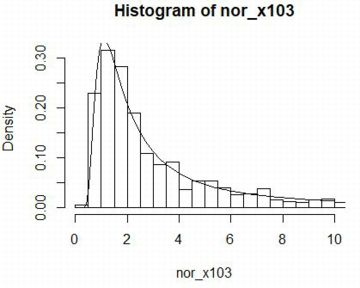
下図では,Pareto(1,1) にしたがう乱数1000個からなるベクトルを
「pare2」としました.「summary」を調べて左側だけを切り出しました.
第3四分位数(3rd Qu.)は 3.984,最大値は 1062.54です.
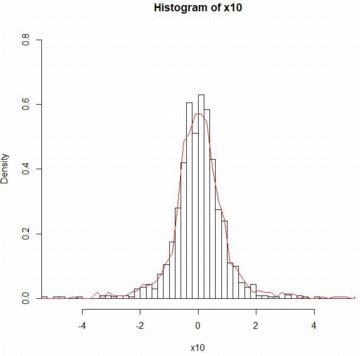
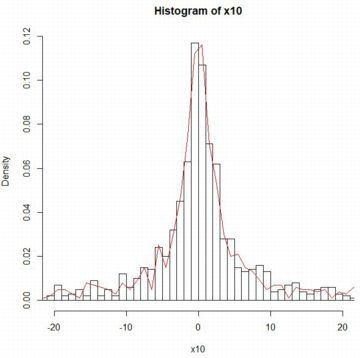
次に,区間 [1,1063] を1刻みにしてヒストグラムを作成し,
区間 [1.01,15] の範囲で確率密度関数「dPareto(x,1,1)」の
グラフを「add=T」として重ね合わせました. |
|
|
|
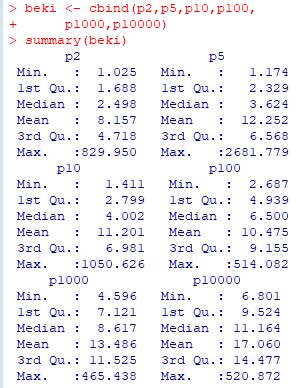
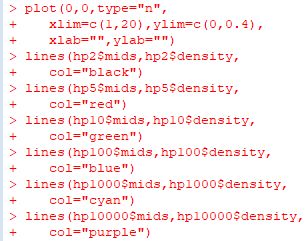
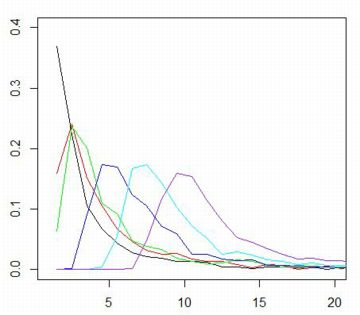
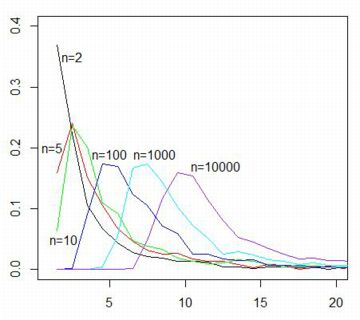
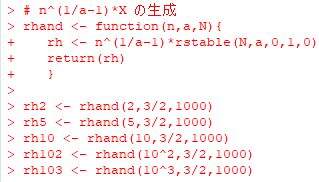
■標本平均の分布 dPareto(x,1,1) は \(\small f(x)=\frac1{x^2}\) ということです. 簡単な計算 から分かるように,この確率密度関数は平均も分散も存在しません. 中心極限定理によれば,平均や分散が存在するような確率分布では, 標本数を増やしていくと標本平均の分布は正規分布で近似されます. ここでは,平均や分散が存在しない「ベキ分布」にしたがう 乱数を「rPareto(n,1,1)」により発生させて, その標本平均がどのような分布になるかを調べてみましょう. 最初に,n個の標本平均からなる要素数N個のベクトルを生成する関数を定義します.
実は,ベキ分布にしたがう確率変数の平均は「安定分布」に 近づいていくことが証明されています(参照). また,Pareto(1,2/3)とPareto(1,3/2)の場合は, 標本平均の収束先の確率密度関数を特殊関数を用いて 表すことができます.それを実際に行ったのが, 次のパッケージ「gsl」での解説です. |
|
|
|
GNU Science Library(gsl) [script] 「R」のパッケージに「gsl」があります. これは「GNU Science Library(GSL)」と呼ばれるもので, 他方面にわたる数学関数を取りまとめたC言語のライブラリーです. 「gsl」は,そのライブラリーに含まれる幾つかの関数を 「R」でも利用できるようにしたものです。 |
|
|
|
■「GSL」とは 「GSL」ではどのような関数を利用できるかは下記を参照してください. [1]は「GSL」の解説書(和文)であり膨大な関数群が登録されています. [2]は「R」での利用例が紹介されています(英文). なお,「GSL」に登録されている関数は, C言語に堪能であれば「gnuplot」で 利用することもできます. |
|
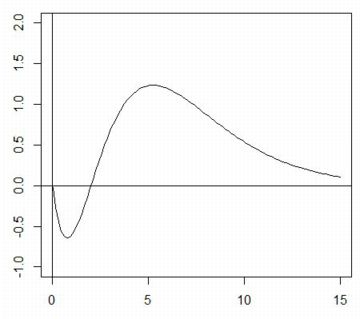
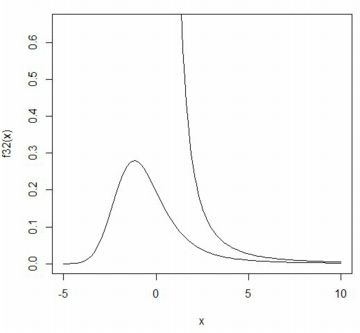
■合流型超幾何関数 ここでは,「ベキ分布」での解析で必要となることから 合流型超幾何関数の使用例を述べます. 合流型超幾何関数は合流型超幾何微分方程式 \[\small zy''+(b-z)y'-ay=0\] の解として定義されます. この微分方程式の一般解は \[\small y=c_1M(a,b,z)+c_2U(a,b,z)\] で表され, \(\small M(a,b,z)\) は第1種合流型超幾何関数, \(\small U(a,b,z)\) は第2種合流型超幾何関数 と呼ばれ,次式で定義されます. (参照1,参照2). \[\small \begin{align*} M(a,b,z) &=1+\frac{a}{b}z+\frac{a(a+1)}{b(b+1)}\frac{z^2}{2!}\\ &+\cdots=\sum_{n=0}^{\infty}\frac{(a)_n}{(b)_n}\frac{z^n}{n!}\\ U(a,b,z) &=\frac{\Gamma(1-b)}{\Gamma(a-b+1)}M(a,b,z)\\ &+\frac{\Gamma(b-1)}{\Gamma(a)}z^{1-b}\\ &\quad \times M(a-b+1,2-b,z) \end{align*}\] なお,\(\small (a)_n=a(a+1)(a+2)\cdots (a+n-1)\) であり, \(\small \Gamma(z)\) はガンマ関数です. この第2種合流型超幾何関数は,「gsl」では「hyperg_U」として登録されています. さらに,この関数を用いると,「(第2種)ホイッタカー(Whittaker)関数」 なるものが次式で定義されます.この関数は,次の項目で述べる ベキ分布にしたがう確率変数の和の分布を考えるときに必要となります. \[\small \begin{align*} W_{k,m}(z)&=e^{-\frac{z}{2}}z^{m+\frac12}{}\\ &\times U(m-k+\frac12,1+2m,z)\end{align*}\] たとえば,\(\small w(2,1/2,x)\) のグラフは下図です. WolframAlphaでも同じグラフが描画されています.
|
|
|
|
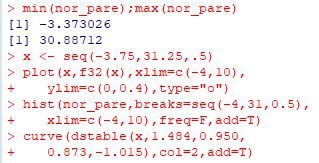
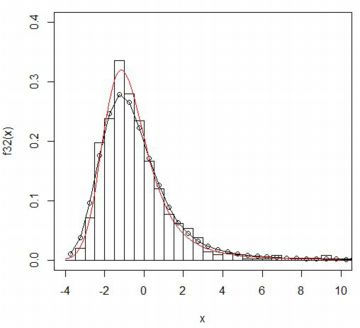
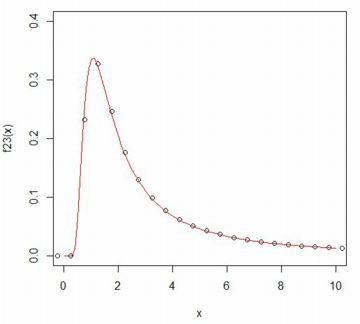
■ベキ分布の和 このホイッタカー関数を利用すると, ベキ分布 \(\small f(x)=\frac{\alpha}{x^{\alpha+1}}~(x\gt 1, \alpha\gt 0)\) にしたがう確率変数の和の分布について考えることができます. ベキ分布の確率密度関数は単純ですが, この分布にしたがう確率変数の和の分布は簡単な式で表すことはできません. この分布は指数 \(\small \alpha\) の値によっては 平均や分散が存在するとは限らないため,中心極限定理は適用できません. しかし,分散が存在しない確率分布の場合の中心極限定理に対応するものとして, 「一般化中心極限定理」があります.それによると, ベキ分布にしたがう互いに独立な確率変数の和を \(\small S_n\) とすると, 定数 \(\small a_n, b_n\) に対して \[\small \lim_{n\to\infty} {\rm P} \left(\frac{S_n-b_n}{a_n}\leq x\right) =F_{\alpha}(x)\] を満たすような安定分布 (Rでの解説)が存在することが証明されています (参照, p.12(19)) . 右辺は,指数 \(\small \alpha\) を持つ安定分布(Maximaでの解説)の累積分布関数です.(実際には,他に 3つのパラメータを持つ.) ここで,定数 \(\small a_n, b_n\) は \(\small a_n=n^{1/{\alpha}}C_{\alpha}\) であり,\(\small C_{\alpha}\) は次式で表されます. \[\small C_{\alpha} =\begin{cases} \small \left(\Gamma(1-\alpha)\cos\left(\frac{\pi \alpha}{2}\right)\right)^{1/{\alpha}} & (\alpha\ne 1) \\ \displaystyle \quad \frac{\pi}{2} &(\alpha=1) \end{cases}\] \(\small b_n\) は,\(\small 0\lt \alpha\lt 1,~ \alpha=1,~ 1\lt\alpha \lt 2\) に応じて,それぞれ \[\small b_n=\begin{cases}\small\quad 0\\ \displaystyle\small n\log{n}+n\left(1-C-\log\frac2{\pi}\right)\\ \displaystyle\small \frac{n\alpha}{\alpha-1} \end{cases}\] ここで,\(\small b_n\) の2行目は近似式であり,\(\small C\) はオイラー定数 (\(\small 0.5772156649\cdots\))です. 通常の統計の授業で安定分布に触れられることはありませんが, 現実社会のいろいろな現象を解析する上で安定分布は極めて重要な確率分布です. しかし,その確率密度関数を初等関数で書き表すことができるのは, 正規分布,コーシー分布,そしてレビ分布に限られ, それぞれ \(\small \alpha=2, 1, 0.5\) の安定分布に対応します (後半の2つの分布は平均も分散も存在しません). しかし,特殊関数であるホイッタカー関数を利用すると, \(\small \alpha=\frac23, \frac32\) の場合も式で書き表すことができます. それぞれの確率密度関数を \(\small f_{2/3}(x), f_{3/2}(x)\) とすると, 次の式で表されます(参照,p.10(15〜18)). \(\small f_{2/3}(x)~(x\gt 0)\) は\[\small \sqrt{\frac{3}{\pi}}\frac1{x}\exp\left(\small -\frac{16}{27x^2}\right) W_{1/2,1/6}\left(\small \frac{32}{27x^2}\right)\] \(\small f_{3/2}(x)\) は,\(\small x\lt 0, x\gt 0\) の場合に, それぞれ \[ \begin{cases}\small -\sqrt{\frac{3}{\pi}}\frac1{x}\exp\left(\frac{x^3}{27}\right) W_{1/2,1/6}\left(-\frac{2x^3}{27}\right)\\ \small \frac1{2\sqrt{3\pi}}\frac1{x}\exp\left(\frac{x^3}{27}\right) W_{-1/2,1/6}\left(\frac{2x^3}{27}\right) \end{cases} \] 以下では,\(\small \alpha=\frac23, \frac32\) の場合の ベキ分布 \(\small f(x)=\frac{\alpha}{x^{\alpha+1}}\) にしたがう乱数を発生させて,このことを実際に確かめてみましょう.
[1] \(\small \alpha=\frac23\) の場合
|
|
|
|
[2] \(\small \alpha=\frac32\) の場合
|
|
|
|
安定分布 [script] |
|
■安定分布とは 通常の統計の教科書では平均や分散が存在するような確率分布しか扱われませんが, 実際の現象では「ベキ分布」のように 平均や分散が存在しない確率分布があります. そのような確率分布では中心極限定理は適用できないので, いろいろな統計量を正規分布に帰着させることができません. 平均や分散が存在しない場合には「一般化中心極限定理」があり, 「安定分布」と呼ばれる確率分布が中心になります. 安定分布は,確率変数 \(\small X\) の独立なコピーを \(\small X_1, X_2,\ldots,X_n\) とするとき, \[\small X_1+X_2+\cdots+X_n\overset{d}{=}a_nX+b_n\] を満たすような定数 \(\small a_n, b_n\) が 存在するような確率分布として定義されます. 記号「\(\small \overset{d}{=}\)」は,両辺の分布が一致することを示します. 正規分布は,この性質を満たすので安定分布です.実際, 確率変数 \(\small X\) が正規分布 N\(\small (\mu,\sigma^2)\) にしたがえば, 標準化した \(\small Z=(X-\mu)/\sigma\) は \(\small X=\sigma Z+\mu\) と表され, \(\small Z\) は標準正規分布 N(0,1)にしたがいます. さらに,大きさ \(\small n\) の標本平均 \(\small \bar{X}\) も 正規分布 N(\(\small \mu,\sigma^2/n\)) にしたがうので, それを標準化した \(\small (\bar{X}-\mu)/(\sigma/\sqrt{n})\) も 標準正規分布 N(0,1) にしたがいます.分布が一致するので \[\small \frac{\bar{X}-\mu}{\sigma/\sqrt{n}} \overset{d}{=}Z\] と表せます. \(\small \sigma Z=X-\mu\) を代入して 整理すると \[\begin{align*}\small \small X_1+X_2+&\small \cdots+X_n\\ &\small \overset{d}{=}\sqrt{n}X+(n-\sqrt{n})\mu \end{align*}\] と表されます. これは,同一の確率分布にしたがう独立な確率変数の和が 同じ分布にしたがう確率変数の1次式の分布と一致することを示しています. 安定分布は,この関係を平均や分散が存在しないような確率分布に 拡張して考えて得られたものです. 安定分布は聞き慣れない確率分布ですが,平均や分散が存在する正規分布や, それらが存在しないコーシー分布をも含む広い範疇の確率分布です. この確率分布は,確率密度関数をフーリエ変換した式で特徴づけられます. それをフーリエ逆変換して確率密度関数を初等関数で表すことができるのは, 正規分布,コーシー分布,そしてレビ分布に限られます. 詳細は「こちら」(Maxima利用)を参照してください. |
|
|
|
■安定分布のパッケージ「fBasics」 安定分布を扱うパッケージとして,「R」には「fBasics」 が登録されています(ドキュメント[pdf]). しかし,このパッケージを読み込むだけでは不十分で, 他に「stabledist」「mgcv」「tcltk」も読み込む必要があります. さらに,ヒストグラムを描画しやすい「truehist」を使うために「MASS」も 読み込んでおいた方が良いようです. 以下では,それらを読み込み済みとします. 「fBasics」でWeb検索すると, 富士通のパソコンに組み込まれていた「FBASIC」に関するものが 多数検索されますが, 「fBasics」は経済関係(Finance)のデータを分析するための基本パッケージであり, 膨大なデータを解析するための多数の関数が登録されており, 列ごとの分散や標準偏差などをまとめて求めることもできます(colVars,colSds). さらに,一連の関数群の中に安定分布に関する下記のような関数があります.
|
|
|
|
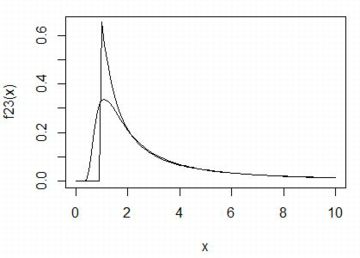
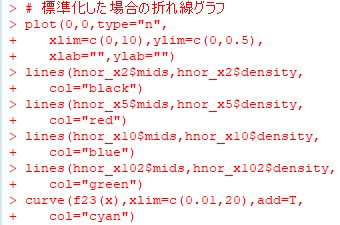
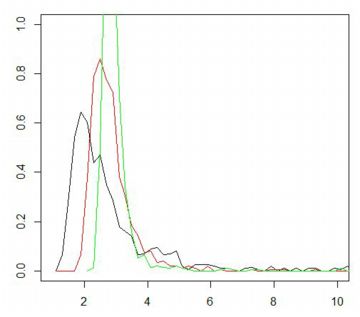
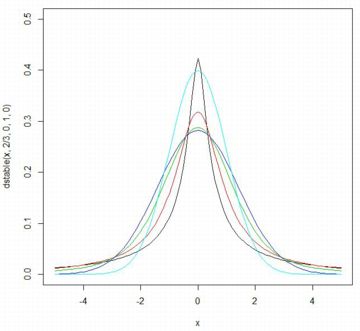
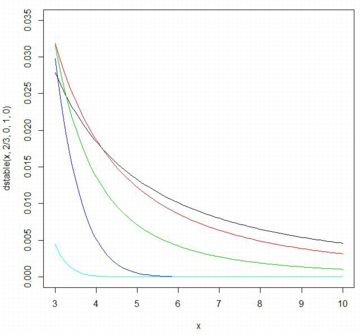
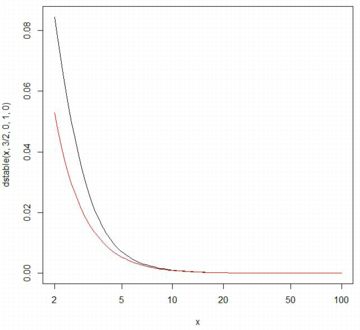
■確率密度関数 以下では,\(\small \gamma=1, \delta=0\) とします. 歪度指数を \(\small \beta=0\) として, \(\small \alpha=\frac23(黒), 1(赤), \frac32(緑), 2(青)\) の場合の確率密度関数の グラフを描画すると下図のようになります.指数の値が大きくなるにつれ, 頂点部分が下がってきます.シアンは標準正規分布 N(0,1) であり, 安定分布の密度関数では 「dstable(x,2,0,1/sqrt(2),0)」です.
|
|
|
|
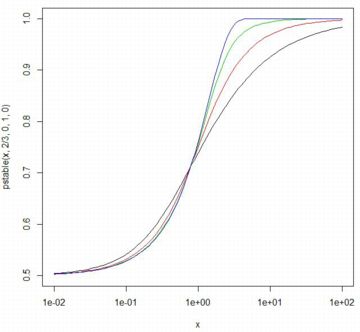
■累積分布関数 下図では,\(\small \beta=0\) の場合の累積分布関数を示しました. 横軸は対数軸です.
|
|
|
|
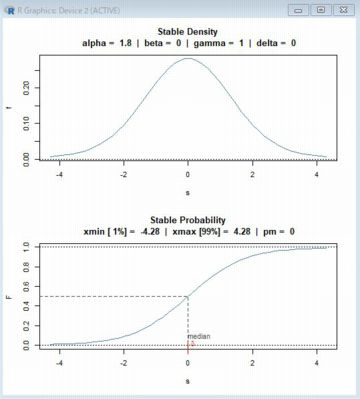
■stableSlider 上記では個別の関数を指定してグラフを描画しましたが, 「stableSlider」を利用すると, ボタンをスライドさせて4つのパラメータを インターラクティブに変化させながらグラフを確認することができます. この関数を利用するには,「fBasics」の他に「tclck」も読み込んでおく必要があります. 最初に「stableSlider()」を実行すると,左側にスライドさせるボタンが現れます.
ボタンをスライドさせると グラフがインターラクティブに変化します. いろいろと動かしてみることで,各パラメータの意味を把握することができます. 下段の累積分布関数では,下位と上位のそれぞれ1%点の値も表示されます. 「pm」ではパラメータの定義の仕方を選択します. 3種類から選択できますが,その意味を把握するのは専門的すぎます. 通常はデフォルトの「pm=0」でよいと思われます. このページの画面はすべて「pm=0」の場合のグラフです. |
|
|
|
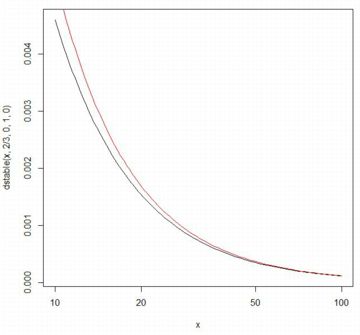
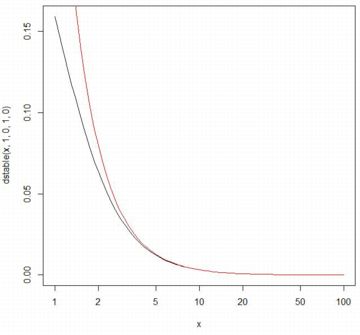
■裾部分の漸近近似 安定分布の裾部分は,ベキ関数で漸近近似することができます. 一般に,安定分布 \(\small S(\alpha,\beta,\gamma,\delta)~(0\lt \alpha\lt 2)\) の 確率密度関数を \(\small f(x)\),累積分布関数を \(\small F(x)\) とすると, \(\small C_{\alpha}=\frac1{\pi}\Gamma(\alpha)\sin\frac{\alpha\pi}{2}\) に対して 次のことが成り立ちます(参照, (p.5)). \[\small 1-F(x)\sim (1+\beta)C_{\alpha}x^{-\alpha}\] \[\small f(x)\sim \alpha(1+\beta)C_{\alpha}x^{-(\alpha+1)}\] このことを,実際に確認してみましょう. 最初に,係数と右辺の関数を定義します.
\(\small \alpha=\frac23, \beta=0\) のとき.
\(\small \alpha=1, \beta=0\) のとき.
\(\small \alpha=\frac32, \beta=0\) のとき.
|
|
|
|
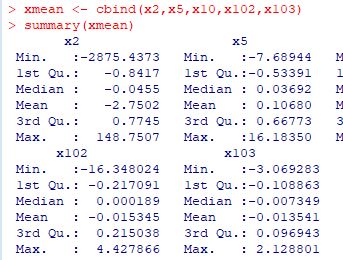
■確率変数の和の分布 安定分布の定義によれば, 確率変数 \(\small X\) の独立なコピー \(\small X_1, X_2, \ldots,X_n\) に対して \[\small X_1+X_2+\cdots+X_n\overset{d}{=}a_nX+b_n\] が成り立つような定数 \(\small a_n, b_n\) が存在します. 指数 \(\small \alpha\) の安定分布の場合は \(\small a_n=n^{\frac1{a}}\) です [参照,(8)]. \(\small b_n=0\) のときは厳密に安定であるといわれます. 以下、乱数を利用して,このことを確認します. 和の値は大きくなるので,平均で考えると, \[\begin{align*}\small \frac1{n}(X_1+X_2&\small +\cdots+X_n)\\ &\small \overset{d}{=}\frac{n^{\frac1{a}}}{n}X+\frac{b_n}{n}\end{align*}\] を考えることになります. 最初に,平均からなるベクトルを生成する関数を定義して,たとえば \(\small S(\frac32,0,1,0)\) にしたがう乱数平均からなるベクトルを生成します.
|
|
|
|
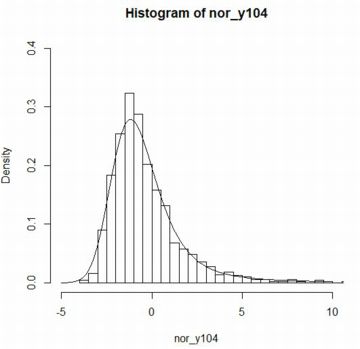
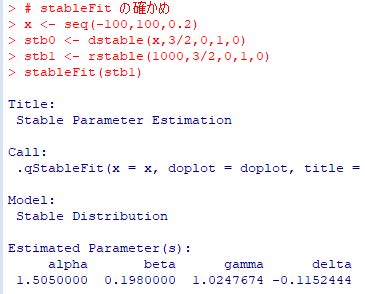
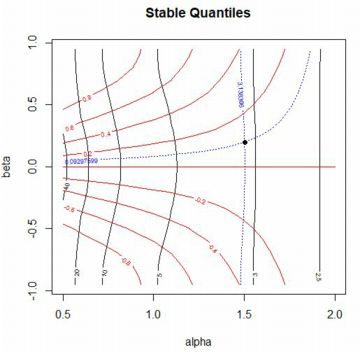
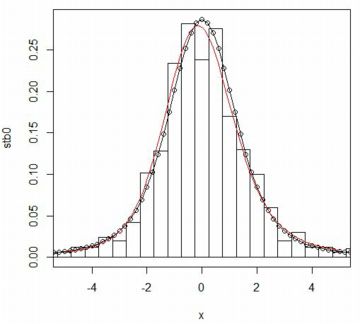
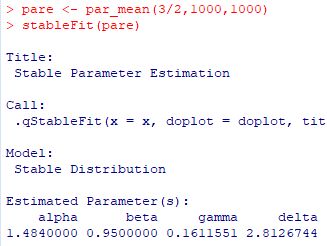
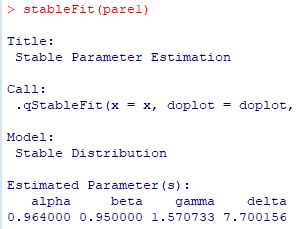
■stableFit パッケージ「fBasics」には,与えられたデータから 安定分布の4つのパラメータを推定する関数が含まれています. 「stableFit」である(参照,(p.30)). 試みに,\(\small S(3/2,0,1,0)\) にしたがう乱数を発生させて, どのようなパラメータとして返されるかを確かめてみましょう. 最初に,\(\small [-100,100]\) を 0.2刻みにした値を用意し, その値での確率密度関数の値を「stb0」とします. 次に,要素数1000個の乱数を発生させて「stb1」とします. その値からパラメータがどのように推定されるかを 「stableFit(stb1)」により確かめます. この関数の適用制限は \(\small \alpha\gt 0.6\) になっています.
★ 「fBasics」を読み込むと, 他の分布でもパラメータを推定する関数があります.x をデータとするとき, たとえば,「nFit(x)」で 正規分布の平均と標準偏差の推定とグラフが表示され, 「tFit(x)」でt分布の自由度の推定とグラフが表示されます(図は略). |
|
|
|
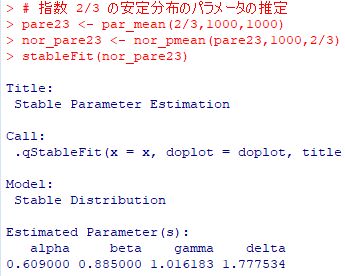
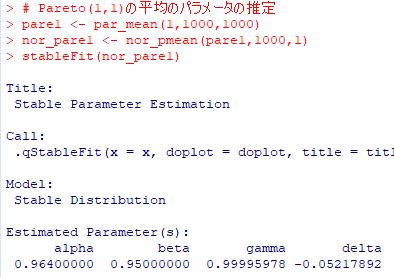
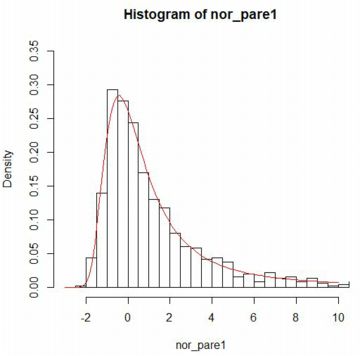
■ベキ分布の和の分布 「ベキ分布の和」の箇所では, ベキ分布 Pareto(1, 3/2), Pareto(1, 2/3) にしたがう 確率変数の和の分布は安定分布に収束することをみました. 「stableFit」を利用して,その安定分布のパラメータの値を推定してみましょう. なお,ここでは,パッケージの「Pareto」と 「gsl」を読み込み済みとし, その箇所で定めた諸関数をそのまま利用することとします. 使用するのは,下記の関数です.
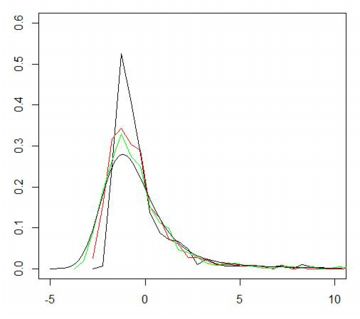
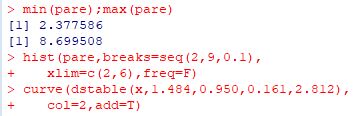
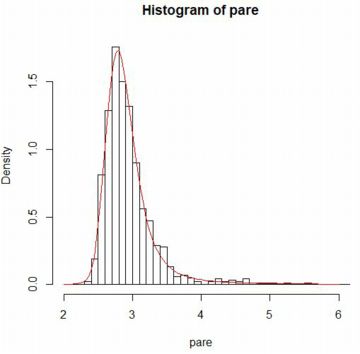
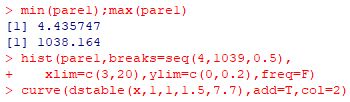
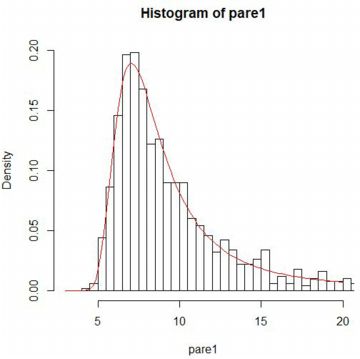
下図は,Pareto(1, 3/2) にしたがう乱数を用いて,1000個平均の値からなる 大きさ1000のベクトルに「stableFit」を適用したものです.
|
|
|
|
[2] Pareto(1, 2/3) の場合 同様にして,\(\small \alpha=\frac23\) の場合の 確率密度関数 \(\small f_{2/3}(x)\) について, 他の3つのパラメータの推定を試みます.
|
|
|
|
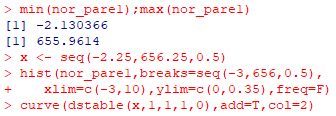
[3] Pareto(1,1)の場合 このベキ分布の確率密度関数は \(\small 1/x^2\) です. この分布にしたがう確率変数の平均がどのような分布を示すかは, すでに「標本平均の分布」の箇所で調べました. 以下では,標準化した場合のパラメータについて同様の推定を試みます.
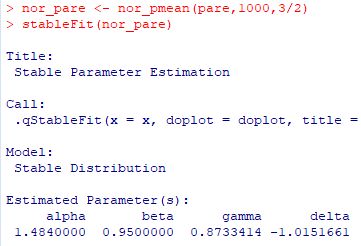
★以上の [1]〜[3] の結果をみると,Pareto(1, \(\small \alpha\)) に したがう乱数平均を標準化すると,安定分布 S(\(\small \alpha, 1, 1, \delta\)) に 近づいていくように思われ,\(\small \alpha=1\) のときは \(\small \delta=0\), \(\small \alpha\lt 1\) のときは \(\small \delta\gt 0\),そして \(\small \alpha\gt 1\) のときは \(\small \delta\lt 0\) であるように思われます. |
|
|
|
レビ分布 [script] |
|
■レビ分布とは レビ分布は,標準正規分布 N(0,1) にしたがう確率変数を \(\small Z\) とするとき, \(\small 1/Z^2\) のしたがう確率分布として定義され,確率密度関数は次式で表されます (参照). \[\small f(x)=\frac1{\sqrt{2\pi}}x^{-\frac32}e^{-\frac1{2x}}\quad (x\gt 0)\] \(\small U=1/Z^2\) に対して \(\small X=\mu+\sigma U~(\sigma>0)\) とおくと,\(\small X\) の確率密度関数は次式で表されます (参照). \[\small \sqrt{\frac{\sigma}{2\pi}}(x-\mu)^{-\frac32} \exp\left(-\frac{\sigma}{2(x-\mu)}\right)\quad (x\gt \mu)\] この確率分布を Levy(\(\small \mu, \sigma\)) で表すことにすると, この分布は安定分布であり S(\(\small 1/2, 1, \sigma, \mu+\sigma\)) と対応します(参照). したがって,Levy(0,1) は S(\(\small 1/2,1,1,1\)) と対応します. この確率分布は,平均も分散も存在しません. 「R」の標準機能にレビ分布は含まれていないので, この分布を扱うには新たなパッケージを読み込む必要があります. たとえば,「rmutil」(Utilities for Nonlinear Regression and Repeated Measurements Models)というパッケージにレビ分布に関連する関数が登録されています (Document). このパッケージを「パッケージのインストール」を利用してインストールして, 「library(rmutil)」により読み込ませます. また,安定分布のパッケージ(stabledist)と「truehist」を登録している パッケージ「MASS」も読み込んで,以上のことを実際に試してみましょう.
|
|
|
|
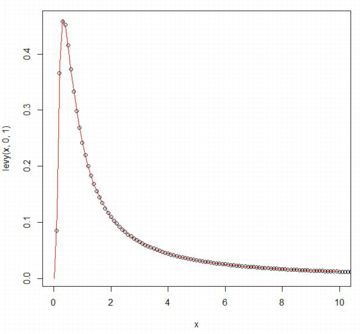
確率密度関数のグラフ 最初に,レビ分布の確率密度関数について確認します. まず,前述の確率密度関数を「levy(x, m, s)」として定義して 「levy(x,0,1)」を点列で描画し,「rmutil」に登録されている レビ分布の確率密度関数「dlevy」のグラフと比較します. 当然ながら,同じであることが確認できます.
|
|
|
|
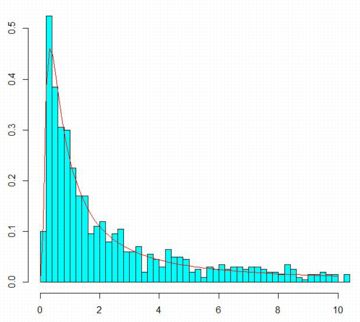
N(0,1)の2乗の逆数の分布 レビ分布は,標準正規分布 N(0,1) にしたがう確率変数 X に対して,1/x^2 の 分布として定義されます.このことを,実際に確認してみましょう. ただし,標準正規分布は 0 の近くの値が多く,その値の2乗の逆数をとると 値が非常に大きくなります.そのため, ヒストグラムの描画には時間がかかり,場合によっては描画できない場合があります. そのため,下記のベクトル「x」は何度か作成して, 最大値が5桁程度の場合で試した方が良いでしょう. 下記の値は8回目で生成されました.
|
|
|
|
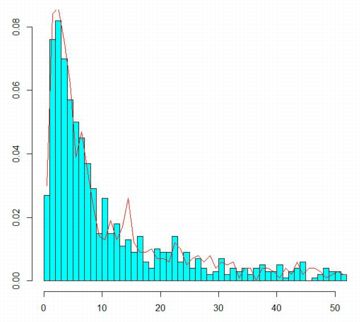
平均の分布 次に,前と同様にして レビ分布が安定分布であることを確認します. レビ分布の指数は \(\small \alpha=\frac12\) であるので, 厳密に安定とすると,\(\small a_n/n=n^{1/\alpha}/n=n\) となるので, \[\begin{align*}\small \frac1{n}(X_1+X_2&\small +\cdots+X_n)\\ &\small \overset{d}{=}nX\end{align*}\] となるはずです. まず,必要な関数を定義します.
|