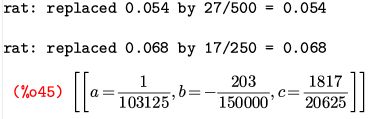「Maxima」を活用して数学の学習ロードを駆け抜けよう!
(注) MathJaxを使用しているので、 スマホでは表示に時間がかかることがあります。
モバイル利用(Android)でのメニュー選択は、 SiteMapを利用するか、 「長押し」から「新しいタブを開く」を選択してください。
| ■ 数式処理ソフト「Maxima」を活用した数学学習 [Map] |
|
| ||||
|
| ||||
| [御案内] 「Maxima」(マキシマ)は,フリーの数式処理ソフトです. 有料の Mathematica や Maple に劣らないレベルの数式処理が可能であり, Linux,Windows,MacOSのみならず,Android版もあります. ここでは,数学学習での Maxima の活用法について解説します. | ||||
|
[お知らせ] スマホ(Android)版Maximaの解説本を出版しました. 計算問題やグラフの確認をするときに非常に重宝します. フリーソフトなので一度試してみてください. PC版のコマンドレファランスとしても利用できます。
| ||||
|
| ||||

| ■数学学習での活用 |
|
|
以下では,「TeXmacs」+「Maxima」の画面で基本的な使い方を解説します. |
| 確率・統計 |
| 統計に特化したソフトウェアとしては,SPSS,SAS,Rなどが有名ですが, Maximaにも統計向けのパッケージが備わっています. |
|
|
|
単回帰分析 単回帰分析では, 目的変数を \(\small Y\), 説明変数を \(\small X\) とするとき, 与えられたデータを「最も良く近似する1次式」を求めます. 「最も良く近似する」ということをどのように考えるかが問題ですが, 設定した式で推定される値と実際の値との差を求めて, その平方和が最小になるように定めます. この考え方は「最小二乗法」と呼ばれ,いろいろな場面で利用されます. | ||||||||||||
|
最小二乗法 コマンド(linear_regression)に データ(行列)を入力すると分析結果が得られますが, ブラックボックスとして利用するのではなく, どのようにして結果が得られているのかも 理解した上で利用すべきでしょう. ここでは,基本となる「最小二乗法」の考え方について解説します. 今,\(\small (X, Y)\) の具体的なデータを \(\small (x_1, y_1), (x_2, y_2), \ldots, (x_n, y_n)\) とすると,\(\small Y=b+mX\) による \(\small x=x_i\) のときの \(\small y_i\) の推測値は \(\small \hat{y}_i=b+mx_i\) です. 最小二乗法は,実際の値との差の平方 \(\small (y_i-\hat{y}_i)^2\) を合計して \[\small \sum_{i=1}^{n}\left\{y_i-(b+mx_i)\right\}^2\] が最小になるように \(\small b, m\) の値を定めます. \(\small (x_i, y_i)~(1\leq i\leq n)\) の値は与えられるので, この式は \(\small b, m\) の関数です. それを \(\small F(b, m)\) とおくと, 結局は2変数関数 \(\small F(b, m)\) の最小値を求める問題になり, そのような点では極値になっていると考えられます. 1変数関数 \(\small f(x)\) の場合は, \(\small x=a\) で極値を取れば \(\small f'(a)=0\) が成り立ちます. 偏微分法(多変数関数の微分法)で学ぶように, 2変数関数でも同様のことが成り立ちます. つまり,\(\small F(b, m)\) が極値をとれば, その点で \(\small b, m\) で微分するといずれも偏導関数の値は\(0\)になり \[\small \frac{\partial}{\partial b}F(b, m)=0,\quad \frac{\partial}{\partial m}F(b, m)=0\] が成り立ちます. \(\small \partial\) は,2変数以上の場合の微分を表す記号です.ここで,実際に \(\small F(b,m)\) を微分すると,合成関数の微分法により \[\begin{align*} \small \frac{\partial F}{\partial b} &\small =2\sum_{i=1}^{n}\left\{y_i-(b+mx_i)\right\}\cdot (-1)~ (1)\\ &\small =-2\left(\sum_{i=1}^{n}y_i-bn-m\sum_{i=1}^{n}x_i\right)\\ &\small =0\\ \small \frac{\partial F}{\partial m} &\small =2\sum_{i=1}^{n}\left\{y_i-(b+mx_i)\right\}\cdot (-x_i)\\ &\small =-2\left(\sum_{i=1}^{n}x_iy_i-b\sum_{i=1}^{n}x_i\right.\\ &\small \left. -m\sum_{i=1}^{n}x_i^2\right)=0\quad (2) \end{align*} \] となります.したがって,\(\small b, m\) は次の連立1次方程式を満たします. \[ \begin{cases}\small\displaystyle m\sum_{i=1}^{n}x_i^2+b\sum_{i=1}^{n}x_i=\sum_{i=1}^{n}x_iy_i ~ (3)\\ \small \displaystyle m\sum_{i=1}^{n}x_i+bn=\sum_{i=1}^{n}y_i\qquad (4) \end{cases}\] これを \(\small m\) について解くと次のようになります. \[\small m=\frac{\displaystyle n\sum_{i=1}^{n}x_iy_i-\sum_{i=1}^{n}x_i\sum_{i=1}^{n}y_i} {\displaystyle n\sum_{i=1}^{n}x_i^2-\left(\sum_{i=1}^{n}x_i\right)^2} \] ここで, 共分散 \(\small s_{xy}=\displaystyle \frac1{n}\sum_{i=1}^{n}(x_i-\bar{x})(y_i-\bar{y})\) は, \[\small s_{xy}=\frac1{n}\sum_{i=1}^{n}x_iy_i-\bar{x}\bar{y} \] と変形することができ,分散 \(\small\displaystyle \sigma_x^2= \frac1{n}\sum_{i=1}^n(x_i-\bar{x})^2\) は \[\small \sigma_x^2=\frac1{n}\sum_{i=1}^{n}x_i^2-(\bar{x})^2\] と表すことができることに注意すると, \(\small m\) の分子・分母を \(\small n^2\) で割ることにより \[\small m=\frac{s_{xy}}{\sigma_x^2}\] と簡潔な式で表されます. 一方, \(\small b\) の値は,(4)より \[\begin{align*}\small b&\small =\frac1{n}\sum_{i=1}^{n}y_i-m\cdot \frac1{n}\sum_{i=1}^{n}x_i\\ &\small =\bar{y}-m\cdot\bar{x}\end{align*}\] となります. つまり,2変量 \(\small X, Y\) について, \(\small \displaystyle \sum_{i=1}^nx_i, \sum_{i=1}^ny_i, \sum_{i=1}^nx_i^2, \sum_{i=1}^nx_iy_i\) の値が分かれば, \(\small b, m\) の値を計算できることになります. ここで, 実際の値と推測値との差の平方の合計を \(\small n\) で割った平均の式 \[\begin{align*} &\small \frac1{n}\sum_{i=1}^{n}(y_i-\hat{y}_i)^2\qquad (5)\\ &\small =\frac1{n}\sum_{i=1}^{n}\left\{y_i-(b+mx_i)\right\}^2 \end{align*}\] に,今求めた \(\small b, m\) の値を代入して \[\small \frac1{n}\sum_{i=1}^{n}\left\{(y_i-\bar{y}) -\frac{s_{xy}}{\sigma_x^2}(x_i-\bar{x})\right\}^2\] を計算すると, \[\begin{align*} &\small \sigma_x^2=\frac1{n}\sum_{i=1}^{n}(x_i-\bar{x})^2\\ &\small \sigma_y^2=\frac1{n}\sum_{i=1}^{n}(y_i-\bar{y})^2\\ &\small s_{xy}=\frac1{n}\sum_{i=1}^{n}(x_i-\bar{x})(y_i-\bar{y}) \end{align*} \] であることなどから,(5)は \[\begin{align*} \small \sigma_y^2-\frac{s_{xy}^2}{\sigma_x^2} =\sigma_y^2\left\{1-\left(\frac{s_{xy}}{\sigma_x\sigma_y}\right)^2\right\} \end{align*}\] と変形することができます. ここに現れた \(\small \frac{s_{xy}}{\sigma_x\sigma_y}\) が 相関係数 \(\small r\) です.\(\small r\) の値が 1 に近いほど 推測値と実際の値との差が小さいことなり, データが一つの直線 \(\small y=b+mx\) の近くに分布していることを 示しています.この直線が回帰直線であり, その係数 \(\small b, m\) が回帰係数です. 以上の詳細は, 統計の教科書やWebサイトを 参照してください. | ||||||||||||
|
| ||||||||||||
|
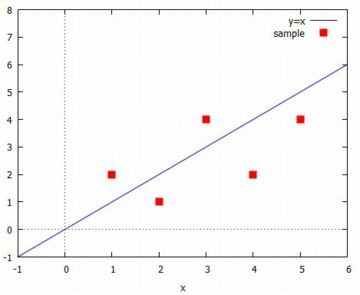
回帰係数の計算 具体的なデータで,この回帰直線 \(\small y=b+mx\) を求めてみましょう. 手計算での検算がしやすいように \(\small X, Y\) の値を次の数値で考えます.
次に,このデータから基本統計量を一つずつ計算していきましょう. 「いろいろな統計量」で解説したように, 平均は「mean」,分散は「var」により求めることができます.
ここではコマンドの使い方の練習として 各列の平均や分散を個別に求めましたが, 元データである行列「dat」を入力すると, (%i20)(%i21)のように,各列の平均や分散が一気に求められます.
| ||||||||||||
|
| ||||||||||||
|
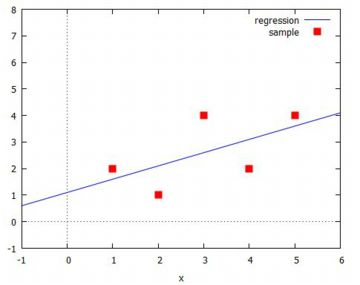
linear_regression 次に,「stats」パッケージに登録されている 線形回帰を求めるコマンド 「linear_regression」を利用して求めてみましょう.
線形回帰を行うには, (%i29)のように(%i2)で定めたデータ行列「dat」を入力するだけです. このコマンドで3列以上の行列を入力すると重回帰分析を行います. いずれも,行列の最後の列を目的変数とする必要があります. 結果は(%o29)のような多岐の内容で表示されますが, これは重回帰分析に対応した出力結果です. マニュアルには記載されていませんが, 単回帰分析 \(\small y=a+bx\) の場合は, 後述する 「simple_linear_regression」を利用した方が 出力結果が分かりやすいようです. また,(%o29)は,「Texmacs+Maxima」での出力です. 最新版のwxMaximaでは,このうち 1,4,5,6,7,8,9,11 の値だけが 表示されるように修正されています. なお,(%o29)の内容について, マニュアルには次のように記載されています.
さしあたっては,回帰係数 \(\small b, m\) の値が求められればよいかと 思います.それが,最初に書かれている「1. b_estimation」の箇所にあります. リストで [b, m] の結果が書かれています. 回帰直線は求められても, それが実際の値をどの程度近似しているのかが気になります. それは,「10. residuals」(残差)の箇所に書き込まれています. 予測値を \(\small \hat{y}\) とするとき, \(\small y-\hat{y}\) の値がリストで出力されています.たとえば, \(\small y_1=2\), \(\small \hat{y}_1=11/10+1/2\cdot 1=8/5\) なので, \(\small y_1-\hat{y}_1=2-8/5=2/5=0.4\) です. 個別の誤差だけ示されても,全体としての近似の良さはどの程度なのでしょうか. それを表す指標として決定係数と呼ばれるものがあります. それは,予測値を \(\small \hat{y}\) とするとき \[\small R^2= 1-\frac{\sum_{i=1}^{n}(y_i-\hat{y}_i)^2}{\sum_{i=1}^{n}(y_i-\bar{y})^2}\] により定義される値です. 分母は実測値の変動を表し,分子は予測値との「ずれ」の変動を表すので, \(\small R^2\) の値が 1 に近いほど分子(つまり「ずれ」)が小さくて 良い予測式といえます.分母は全変動,分子は残差変動と呼ばれています. この値は, \[\small R^2= \frac{\sum_{i=1}^{n}(\hat{y}_i-\bar{y})^2}{\sum_{i=1}^{n}(y_i-\bar{y})^2}\] と表すこともできます.分子は予測値の変動を表します. この2つの式が一致することは,次のようにして分かります. まず,回帰直線を求めるための前提とした式(1)(2)から \[\begin{align*} &\small \sum_{i=1}^{n}(y_i-\hat{y}_i)=0\\ &\small \sum_{i=1}^{n}(y_i-\hat{y}_i)x_i=0 \end{align*}\] であることに注意すると,\(\small \hat{y}_i=b+mx_i\) に対して \[\small \sum_{i=1}^{n}(y_i-\hat{y}_i)\hat{y}_i=0\] が得られます.さらに, \[\begin{align*} &\small (y_i-\bar{y})^2\\ &\small =\left\{(y_i-\hat{y}_i)+(\hat{y}_i-\bar{y})\right\}^2\\ &\small =(y_i-\hat{y}_i)^2+2(y_i-\hat{y}_i)(\hat{y}_i-\bar{y})\\ &\small \hspace{10mm}+(\hat{y}_i-\bar{y})^2 \end{align*}\] と変形できて,右辺の第2項を \[\small 2(y_i-\hat{y}_i)\hat{y}_i-2(y_i-\hat{y}_i)\bar{y}\] と分けて総和を取ると 0 になることから, 次の式が成り立ちます. \[\begin{align*} \small \sum_{i=1}^{n}(y_i-\bar{y})^2 &=\sum_{i=1}^{n}(y_i-\hat{y}_i)^2\\ &\small \qquad+\sum_{i=1}^{n}(\hat{y}_i-\bar{y})^2 \end{align*}\] 右辺の第1項を左辺に移項して \(\small \sum{(y_i-\bar{y})^2}\) で 割れば,\(\small R^2\) の2つの式が一致することが分かります. 特に, 単回帰(\(\small y=b+mx\)) の場合は相関係数の2乗と一致します (参照1, 参照2). ただし,説明変数を増やしていけば「ずれ」は小さくなるので, 定数項を除く説明変数の数を \(\small p\) として, \[\small R^2= 1-\frac{\frac1{n-p-1}\sum_{i=1}^{n}(y_i-\hat{y}_i)^2} {\frac1{n-1}\sum_{i=1}^{n}(y_i-\bar{y})^2}\quad (6)\] で考える場合もあります.これを,自由度調整済みの決定係数といいます. 「11. adc」は,この値を表します(参照). 12〜13の情報量基準も,この回帰式の良さの程度を表す数値です. 他の 2〜8 は,求めた回帰係数の区間推定や「ずれ」の分散に関する情報です. これらの数値を理解するには,推定・検定に関する知識が必要なので, さしあたっては気にしないことです. この表示結果から値を取り出すコマンドもあります. それを行うコマンドは「take_inference」です. 「結果のフォーマット」の箇所を参照してください. | ||||||||||||
|
| ||||||||||||
|
「stats.mac」のコード Maximaの内部では,これらの値をどのようにして計算しているのでしょうか. その計算過程は「stats」パッケージに書かれています. 「load(stats)$」ではなく「load(stats);」とすると, 読み込むパッケージの保存場所が表示されます.最後に書かれているファイル名 「satats.mac」が推定・検定の統計処理を記述しているファイルです. Lisp言語ではなくMaximaのプログラムとして記述されているので, プログラムの知識がある方が見れば, 何をやっているのかを何となく把握することができます. マニュアルでは,線形回帰に関して「linear_regression」しか記載されて いませんが,sats.macをみると, 単回帰を行う「simple_linear_regression」というコマンドもあります. (%o29)の出力は,重回帰に対応した出力です. 単回帰を行う「simple_linear_regression」は後半の1300行以降に記述されており, その中の「estimation」の箇所に単回帰の場合の計算過程が記述されています. 「dat」を入力したデータ行列,回帰直線を \(\small y=a+bx\) として, 次の手順で計算が進められています. /* estimations */下段は,私の理解による「simple_linear_regression」の コードに関するコメントです.
| ||||||||||||
|
| ||||||||||||
|
単回帰による表示結果 下図は,「simple_linear_regression」による データ行列「dat」の分析結果です. 前述の計算手順により計算されたものです.
なお,最新版のwxMaximaでは, (%o43)の半分以下の内容しか表示されません. おそらく,初等的な項目や専門性の高い項目は非表示にしたものと思われます. 表示はされなくても,計算はされています. どのような内容が計算されているのかは 「items_inference」で知ることができます. 「結果のフォーマット」を参照してください.
以上のことを解析するには, 誤差の分布の仕方について幾つかの仮定をする必要があります. 詳細は下記を参照してください. | ||||||||||||
|
| ||||||||||||
|
結果のフォーマット 線形回帰の表示結果を利用してさらなる計算を進めるとき, 結果の数値を取り出すには「take_inference」を利用します. たとえば,(%o29)の回帰係数「b_estimation」の値を[b,m]に割り当てるには, 取り出す項目の先頭に「'」をつけて下図の(%i56)のようにします. 同様にして,出力結果を自分の使用する文字に割り当てることができます. また,表示はされなくても,どのような結果が保持されているかをみるには, 結果を(%oN)とすると「items_inference(%oN);」とします(図は略).
(%o61)での「yosoku_siki」の係数が同じになってます. satats.mac では,予測式を \(\small y=a+bx\) として計算がなされています. (%i56)は前述の解説で予測式を \(\small y=b+mx\) として \(\small [b,m]\) に \(\small [a,b]\) を割り当てたので, 同じ値が割り当てられてしまいました. 改めてやり直したもので示せば良いのですが, このような指定をするときは Maximaで利用されている変数も考慮しながら使用変数を指定する必要があることへの 注意も兼ねてそのまま残しました(言い訳?). 「soukan_keisu」の値は,ちょっと紛らわしいかもしれません. 他の2桁の数と見比べると,3 と 2 の間には若干の空白があります. これは,\(\small 5/(3\cdot 2^{\frac32})\) を示しているので注意が必要です.
ただし,(%i63)の「inference_result」の第3引数で表示内容を指定しても, 私が使用している「Texmacs+Maxima」では第2引数の内容が全部出力されてしまいます. 最新版のwxMaximaで同じ処理をさせると,第3引数の指定通りに出力されました. バージョンが上がるごとに,このような細かい部分の修正が施されているようです. | ||||||||||||
|
|













|
重回帰分析 | ||||||||||||||||||
|
最小二乗法 説明変数を増やして単回帰と同様の1次式での近似を考えるのが 重回帰(多重線形回帰)です.説明変数を \(\small x_1, x_2, \ldots, x_n\), 目的変数を \(\small y\) とするとき,目的変数を最も良く近似する1次式 \[\small y=b_0+b_1x_1+b_2x_2+\cdots+b_nx_n\] を最小二乗法により求めることになります. 簡単のため説明変数が2変数のときを考えて, 変数 \(\small y, x_1, x_2\) のとる具体的な値を, それぞれ \(\small y_i, x_{1i}, \ldots, x_{ni}\) とすると, 単回帰のときと同様に \[\small \sum_{i=1}^{n}\left\{y_i-(b_0+b_1x_{1i}+\cdots+b_nx_{ni})\right\}^2\] が最小になるような係数 \(\small b_0, b_1, \ldots, b_n\) を求めることに なります. 手法は単回帰のときと同様なのですが,変数が増えると式も複雑になります. 説明変数が2つの場合は,次のような計算を行うことになります. \[\small \sum_{i=1}^{n}\left\{y_i-(b_0+b_1x_{1i}+b_2x_{2i})\right\}^2\] を \(\small b_0, b_1, b_2\) の関数とみて \(\small F(b_0, b_1, b_2)\) とします. 最小になる箇所では極値を取ると考えると, \(\small b_0, b_1, b_2\) で偏微分すると 0 になるはずです. 実際に偏微分して \(\small -2\) で割ると次の式になります. なお,和の記号は,単に \(\small \Sigma\) で表しています. \[\begin{cases}\small \sum\left\{y_i-(b_0+b_1x_{1i}+b_2x_{2i})\right\}=0\\ \small \sum{x_{1i}}\left\{y_i-(b_0+b_1x_{1i}+b_2x_{2i})\right\}=0\\ \small \sum{x_{2i}}\left\{y_i-(b_0+b_1x_{1i}+b_2x_{2i})\right\}=0 \end{cases}\] これらを整理して,次の \(\small b_0, b_1, b_2\) に 関する連立方程式(1)が得られます. なお,左辺だけで改行しているのは, スマホでも適切に表示されるようにするためです. \[\left\{\begin{align*} &\small b_0n+b_1\sum{x_{1i}} + b_2\sum{x_{2i}}\\ &\small \hspace{38mm} =\sum{y_i}\\ &\small b_0\sum{x_{1i}}+b_1\sum{x_{1i}}^2 +b_2\sum{x_{1i}x_{2i}}\\ &\small \hspace{38mm} =\sum{x_{1i}}y_i\quad (1)\\ &\small b_0\sum{x_{2i}}+b_1\sum{x_{2i}x_{1i}} +b_2\sum{}x_{2i}^2\\ &\small \hspace{38mm} =\sum{x_{2i}}y_i\\ \end{align*}\right.\] これにより,変量 \(\small x_1, x_2, y\) に関するデータから, 総和 \(\small \sum{x_{1i}}, \sum{x_{2i}}, \sum{y_i}\), 積和 \(\small \sum{x_{1i}x_{2i}}, \sum{x_{1i}y_i}, \sum{x_{2i}y_i}\) そして平方和 \(\sum{x_{1i}{}^2}, \sum{x_{2i}{}^2}\) を求めておけば, この連立方程式(1)を解くことで 係数 \(\small b_0, b_1, b_2\) の値を求めることができます. 第1式を \(\small n\) で割ると, \(\small \bar{y}=b_0+b_1\bar{x_1}+b_2\bar{x_2}\) であることが 分かります. ここで,一般論での議論も視野に入れて, この連立方程式(1)を行列を使って表してみます( 参照). \[\small X= \begin{pmatrix} 1&x_{11}&x_{21}\\ 1&x_{12}&x_{22}\\ \vdots&\vdots&\vdots\\ 1&x_{1n}&x_{2n}\end{pmatrix}\] \[\small \boldsymbol{y}=\begin{pmatrix}y_1\\y_2\\ \vdots\\ y_n\end{pmatrix},\quad \boldsymbol{b}=\begin{pmatrix}b_0\\b_1\\ b_2\end{pmatrix} \] とおくと,連立方程式(1)の右辺は \[\begin{align*} &\small {}^{t} X\boldsymbol{y}\\ &\small =\begin{pmatrix} 1&1&\cdots&1\\ x_{11}&x_{12}& \cdots&x_{1n}\\ x_{21}&x_{22}& \cdots&x_{2n} \end{pmatrix} \!\!\! \begin{pmatrix}y_1\\y_2\\ \vdots\\ y_n\end{pmatrix} \end{align*}\] と表すことができます.一方, (1)の左辺は行列とベクトルの積として \[\small \begin{pmatrix} n&\sum{x_{1i}}&\sum{x_{2i}}\\ \sum{x_{1i}}&\sum{x_{1i}^2}&\sum{x_{1i}x_{2i}}\\ \sum{x_{2i}}&\sum{x_{2i}x_{1i}}&\sum{x_{2i}^2} \end{pmatrix} \!\!\! \begin{pmatrix} b_0\\ b_1\\ b_2\end{pmatrix}\] と表すことができ,左側の行列は \(\small X\) の転置行列を利用すると \[\small \begin{pmatrix} 1&1&\cdots&1\\ x_{11}&x_{12}& \cdots&x_{1n}\\ x_{21}&x_{22}& \cdots&x_{2n} \end{pmatrix} \!\!\! \begin{pmatrix} 1&x_{11}&x_{21}\\ 1&x_{12}&x_{22}\\ \vdots&\vdots&\vdots\\ 1&x_{1n}&x_{2n} \end{pmatrix} \] と表すことができるので, 要するに(1)の左辺は次のように簡潔に表すことができます. \[\small {}^t X X \boldsymbol{b}\] したがって,連立方程式(1)は,行列を用いると 次のように表わされます. \[\small {}^t X X \boldsymbol{b}={}^{t} X\boldsymbol{y} \qquad (2)\] ここで,行列 \(\small X\) は説明変数のデータ行列に 1 だけからなる 列を追加した行列,列ベクトル \(\small \boldsymbol{y}\) は目的変数のデータ列,そして列ベクトル \(\small \boldsymbol{b}\) が求めるべき回帰係数の列です. 目的変数が増えると,\(\small X\) の列数と \(\small \boldsymbol{b}\) の 行数が増えるだけで, 式の形は(2)と全く同じです. 式(2)において \(\small {}^t X X\) の逆行列が存在すれば, 回帰係数 \(\small \boldsymbol{b}\) は \[\small \boldsymbol{b}=({}^t X X)^{-1}\, {}^t X \boldsymbol{y} \quad (3)\] により求めることができます.したがって, 与えられたデータから \(\small X, \boldsymbol{y}\) を 作成して,(3)の右辺の計算をさせれば回帰係数が求められます. | ||||||||||||||||||
|
| ||||||||||||||||||
|
基本統計量からの計算 前述の式(3)を用いて,実際に計算してみましょう. 手計算で確かめやすいように,適当に作った次の例で考えます.
(%o6)のデータ行列「dat」をもとに,
以下ではstats.macの「linear_regression」の箇所に
書かれている計算過程に沿って計算します.
| ||||||||||||||||||
|
| ||||||||||||||||||
|
ここでは,いきなり求めるのではなく,
入力したデータ行列「dat」から連立方程式(1)の係数となっている
各種の統計量を求めて,
この連立方程式を地道に解いて求めてみましょう.
それには,各データに対して
単純和,平方和,積和を求める必要があります.
なお,以下の(%i27)〜(%i48)は,連立方程式(1)に対する理解や, Maximaのいろいろなコマンドの使用法の解説を兼ねた内容です. (%i14)の後に「stats.mac」で行われている計算は, (%i49)以降で解説します.
ここでは個別に計算しましたが,個々の列の平方和や積和の値は, 共分散行列を用いて求めることもできます. 「cov(dat)」により,共分散行列 \[\begin{pmatrix}\small \sigma_1^2& s_{12}& s_{1y}\\ s_{21} & \sigma_2^2 & s_{2y}\\ s_{y1} & s_{y2} & \sigma_y^2 \end{pmatrix}\] が得られます.たとえば,\(\small s_{2y}\) は, \[\begin{align*} \small s_{2y}&\small =\frac1{n}\sum_{i=1}^{n}(x_{2i}-\bar{x_2}) (y_i-\bar{y})\\ &\small =\frac1{n}\sum_{i=1}^{n}x_{2i}y_{i} -\bar{x_2}\bar{y} \end{align*}\] であるので,\(\small s_{2y}\) に2変量の平均の積 \(\small \bar{x_2}\bar{y}\) を加えて \(\small n\) を掛ければ 積和 \(\small \sum_{i=1}^{n}{x_{2i}y_i}\) が求められます.
いずれにしろ,以上により連立方程式(1)で必要とされる係数が求まりました. 入力データ「dat」から作成される連立方程式は下記のようになります. \[\small\left\{\begin{align*} \small 5b_0+15b_1+3b_2&=10\\ \small 15b_0+55b_1+7b_2&=28\\ \small 3b_0+7b_1+55b_2&=-394 \end{align*}\right.\] 方程式を解くコマンド「solve」を利用して解くと, 下記のようになります.
| ||||||||||||||||||
|
| ||||||||||||||||||
|
行列を利用した計算 今度は,逆行列を利用して求めてみましょう. この連立方程式を \(\small A\boldsymbol{b}=\boldsymbol{p}\) とすると, 解は \(\small \boldsymbol{b}=A^{-1}\boldsymbol{p}\) により求められます. Maximaは,連立方程式と変数のリストを指定すると, 係数行列や拡大係数行列を取り出すことができます.
最後に,行列 X を利用して,式(3) \[\small \boldsymbol{b}=({}^t X X)^{-1}\, {}^t X \boldsymbol{y}\] を直接計算して求めてみましょう. これは,実際に「stats.mac」の中で行われているもので, (%i14)からの続きの計算になります.
ここでは,できるだけ個別に計算しましたが, stats.mac内では幾つかの計算がまとめて行われています. いずれにしろ,理論的な計算式に具体例をあてはめながら求めてみることも, 理解を深める上では必要と思われます. 「数式処理」を活用すると,数式を交えた文字計算も含めながら 確認していくことができます. | ||||||||||||||||||
|
| ||||||||||||||||||
|
コマンドの表示結果 多重線形回帰を行うコマンドは「linear_regression」です. 説明変数と目的変数の列データをまとめた行列を「dat」として 入力すると,分析得結果が表示されます. サンプルデータ「dat」を(%o6)として実行すると 下記が表示されます.
それ以外の項目は, 求めた回帰係数や残差の推定に関する内容です. それをどのようにして計算しているのかが気になる方は, stats.macの後半にある「linear_regression」の箇所をみてください. ただし, その内容を理解するには確率分布や推定に関する知識が必要になります. wxMaximaでは,(%o52)のような多数の結果は表示されませんが, 同じ内容は保持しています. 下図は,wxMaximaの画面です.
この結果から予測値を計算するには次のようにします. 以下は,「TeXmacs+Maxima」の画面に戻ります.
| ||||||||||||||||||
|
|











|
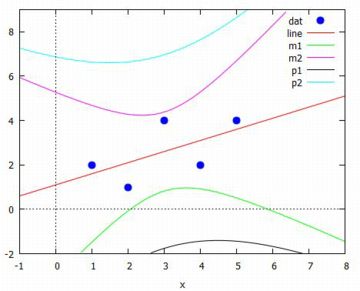
いろいろな回帰 変量間の関係を1次式で説明できないときは, 背景にある状況やデータ分布の様子などから予想される関係式を 自分で見いだす必要があります. そのようなとき,パッケージ「lsquares」に登録されている コマンド「lsquares_estimates」を利用すると, 自分で設定した式で回帰分析をすることができます. |
|
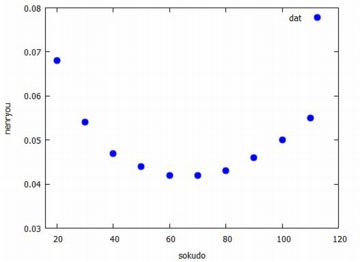
lsquares_estimates 最初に,このコマンドの利用例を見てみましょう. 具体例として,2010年式乗用車の 平均旅行速度(km/h)と燃料消費率(L/km)との関係をみてみます( 参照:表12).
lsquares_estimates(データ行列, 列の名前のリスト, 回帰式, パラメータのリスト) 第1引数は分析するデータ列からなる行列です. 第2引数は,そのデータ列にリストで1列目から順に名前をつけます. 第3引数では,分析したい回帰式を第2引数の変数を使って記述します. したがって,必ずしも最後の列が目的変数である必要はありません. 第4引数は,第3引数で設定した式に使われているパラメータのリストです.「lsquares_estimates」は,設定された回帰式に対して, 最小二乗法により誤差の平方和が最小となるようなパラメータの値を求めます. パラメータに関して得られる連立方程式から厳密解が求められるときは 厳密解を表示します. 厳密解を求めることができないときは, 近似解を求めるパッケージ「lbfgs」に必要な情報を引き渡して 近似計算を行います.回帰式は自分で自由に設定することができます. したがって,回帰係数を求めるだけであれば単回帰や重回帰も 「lsquares_estimates」で行うことができますが, 求めた回帰係数の信頼区間や決定係数のような内容には対応していません.
|
|
|
|
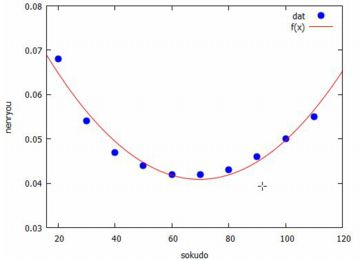
回帰式の残差 「lsquares_estimates」は,回帰式を自由に設定して 与えられたデータを最も良く近似するパラメータを決定します. このコマンドの利用例として, マニュアルでは回帰式を \(\small (z+D)^2=Ax+By+C\) とする場合が紹介されています. しかし,単回帰や重回帰のような多岐にわたる情報は得られません. その後は,得られた係数の値をもとに自分で分析する必要があります. ただし,残差(誤差)を回帰式による左辺と右辺の差とすると, 残差と残差平方の平均を求めるコマンドがあります. 残差は「lsquares_residuals」,残差平方の平均は 「lsquares_residual_mse」により求めることができます. 前者は「residuals」,後者は「residual」なので気をつけてください.
以下では,(%o25)の値が(%o22)の二乗の平均(mean)と一致することを 確認しようとしています. 平均を求めるコマンド「mean」を利用するため,最初に パッケージ「descriptive」を読み込みます.
|
|
|
|
残差平方の平均 「lsquares_estimates」は,設定された回帰式から「残差平方の平均」 が最小になるパラメータを決定しようとします. それを決定するための方程式は,単回帰や重回帰のときと同様に, 指定したパラメータで微分した式を 0 とする連立方程式です. コマンド「lsquares_mse」を利用すると, その連立方程式のもとになる「残差平方の平均」の式を出力させることができます.
|
|
|
|
2次回帰の計算 前項により2次回帰したときの残差平方の平均の式が出力できるので, それをパラメータで微分した式が 0 として得られる連立方程式を, 実際に解いて解が(%o9)となることを確認してみましょう. 微分のコマンド「diff」と, 方程式の解を求めるコマンド「solve」を利用します.
ここで,2次回帰 \(\small y=ax^2+bx+c\) のときの (平均ではなく)残差平方和を \(\small F(a,b,c)\) とすると,それは \[\small \sum_{i=1}^{n}\left\{y_i-(ax_i^2+bx_i+c)\right\}^2\] という式です.重回帰分析のときと同様にすると, \(\small a,b,c\) で微分して 0 であるとして得られる連立方程式は \[\left\{\!\! \begin{align*}\small \sum\left\{y_i-(ax_i^2+bx_i+c)\right\}x_i^2=0\\ \small \sum\left\{y_i-(ax_i^2+bx_i+c)\right\}x_i=0\\ \small \sum\left\{y_i-(ax_i^2+bx_i+c)\right\}\cdot 1=0 \end{align*}\right.\] であり,括弧をはずして整理すると次のようになります. \[\begin{align*}\small a\sum{x_i^4}+b\sum{x_i^3}+c\sum{x_i^2}&\small =\sum{x_i^2y_i}\\ \small a\sum{x_i^3}+b\sum{x_i^2}+c\sum{x_i}&\small =\sum{x_iy_i}\\ \small a\sum{x_i^2}+b\sum{x_i}+cn&\small =\sum{y_i} \end{align*}\] 今度は,この係数を求めることで解いてみましょう.
いろいろな統計ソフトでは, コマンドにデータを入力すれば即座に結果が得られます. 理解を深めるためには,その結果を鵜呑みにする前に, 一度は理論式をもとに自分で求めてみることも必要と思います. その際, Maximaを「紙と鉛筆」代わりに用いて, 煩雑な基本統計量の計算や連立方程式の解法は 数式処理機能を利用すれば, あたかも自分で計算しているかのような感覚で結果を得ることができます. |
|
|
|
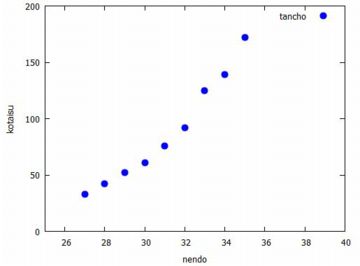
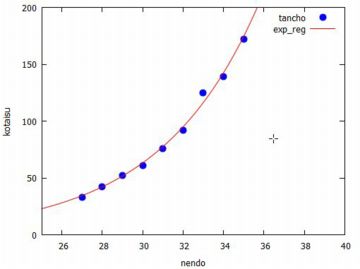
指数回帰 今度は,変量の間の関係を指数関数 \(\small y=ab^x\) で近似する場合を 考えてみましょう. これは,増加率や減少率が一定であるような変化です. 具体例としてタンチョウの個体数変化を取り上げます. 日本のタンチョウは渡り鳥ではなく, 北海道の一部の地域に生息する留鳥です. 一時は絶滅寸前にまで減少しましたが, 特別天然記念物に指定されて保護活動が本格化してから増加に転じています. 自然界の生物として,その個体数はかなり正確に把握されています. 下図では環境省のデータを利用します (参照).
タンチョウは,このまま指数関数的に増え続けていくわけではありません. この後は成長曲線(ロジスティック曲線)に当てはまるような変化をします. その変化は差分方程式で表されて教材化されており, 中学生や高校生にも教授可能です (参照).
非線形連立方程式の近似解を求める方法に, ブロイデン・フレッチャー・ゴールドファーブ・シャノン法(BFGS法)という 方法があり,それを限られたメモリー(Limited memory)でも 実行できるように変更されたものが 「L-BFGS法」であるようです(参照1, 参照2). |
|
|
|
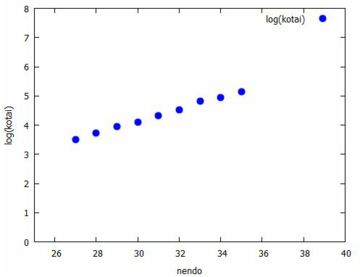
対数変換 いろいろな回帰分析を行う上で, 対数を取った値で分析する場合があります. 対数を取ることを「対数変換」といいます. なぜ対数を取るのか,試みにタンチョウの例で試してみましょう.
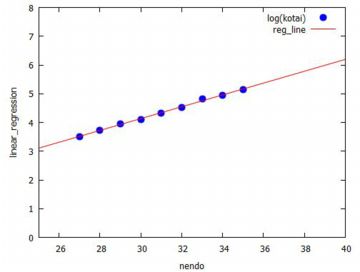
対数を取ると,\(\small 10^n\) のような大きな値や \(\small 10^{-n}\) のような小さな値が取り扱いやすい値に変換されます. 対数関数の変化は極めてゆっくりです.たとえば, 常用対数 \(\small \log_{10}{x}\) の場合は, \(\small x\) の値が 1 から 100 まで変化しても 対数の値は 2 しか変化しません. 説明変数の変化が大きいときに対数を取ると, 変化の小さい変数に変換して考えることができるのです. タンチョウの個体数では, 33羽から172羽までの変化が, 自然対数を取ると 3.497 から 5.147 までの変化に変換されます. 対数を取ると直線的な変化になることが多いので, 今度は単回帰を行ってみましょう. 下図では,(%i27)により 「simple_linear_regression」に引き渡す行列「dat2」を作成し, (%i28)では単回帰を行うコマンドが登録されているパッケージ「stats」 を読み込んでいます. そして,(%i29)により単回帰分析を行っています.
|
|
|