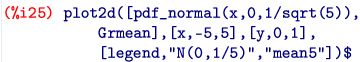「Maxima」を活用して数学の学習ロードを駆け抜けよう!
(注) MathJaxを使用しているので、 スマホでは表示に時間がかかることがあります。
モバイル利用(Android)でのメニュー選択は、 SiteMapを利用するか、 「長押し」から「新しいタブを開く」を選択してください。
| ■ 数式処理ソフト「Maxima」を活用した数学学習 [Map] |
|
| ||||
|
| ||||
| [御案内] 「Maxima」(マキシマ)は,フリーの数式処理ソフトです. 有料の Mathematica や Maple に劣らないレベルの数式処理が可能であり, Linux,Windows,MacOSのみならず,Android版もあります. ここでは,数学学習での Maxima の活用法について解説します. | ||||
|
[お知らせ] スマホ(Android)版Maximaの解説本を出版しました. 計算問題やグラフの確認をするときに非常に重宝します. フリーソフトなので一度試してみてください. PC版のコマンドレファランスとしても利用できます。
| ||||
|
| ||||

| ■数学学習での活用 |
|
|
以下では,「TeXmacs」+「Maxima」の画面で基本的な使い方を解説します. |
| 確率・統計 |
| 統計に特化したソフトウェアとしては,SPSS,SAS,Rなどが有名ですが, Maximaにも統計向けのパッケージが備わっています. |
|
|
|
■いろいろな確率分布 |
|
★世の中の多くのことは、
「正規分布」ではなく「ベキ分布」に従っているようです。
「ベキ分布:リンク集」も参照してください。
[お知らせ]
「べき分布とべき乗則」についてまとめた解説
本を出版します.
べき分布の基礎から「べき分布:リンク集」で扱っている各種のテーマを,
一通りは解説できたのではないかと思っています.
「べき分布」や「べき乗則」に関心を持たれている方はご利用下さい.
(2025.11)

森北出版 (試し読み) (note), amazon, 紀伊國屋, 楽天, 丸善, Honya Club, e-hon いろいろな統計解析を行うには, 特定の統計量がどのような分布をするのかが重要です. Maximaは下記のように多様な分布を扱うことができます.
確率分布に関するパッケージ「distrib」を読み込むと, 確率密度関数,分布関数,分布関数の逆関数,平均,分散,標準偏差,歪度係数, 尖度係数,乱数を個々の確率分布ごとに求めることができます. 詳細は,マニュアルの「52.distrib」を参照してください. |
|
定義と記号 連続的な確率変数 \(\small X\) の 確率密度関数を \(\small f(x)\) とすると, \(\small f(x)\) は次の性質を持ちます. 離散的な確率変数では,\(\small \int\) を \(\small \Sigma\) で 考えることになります. \[\small \begin{align*} &f(x)\geq 0\\ &\int_{-\infty}^{\infty}f(x)\,dx=1\\ &{\rm P}(a\leq X\leq b)=\int_a^bf(x)\,dx \end{align*}\] 確率密度関数 \(\small f(x)\) に対して, 累積分布関数 \(\small F(x)\) は次の式で定義されます. \[\small F(x)=\int_{-\infty}^{x}f(t)\,dt\] 微積分の基本定理により,両辺を \(\small x\) で微分すると, \[\small F'(x)=\frac{d}{dx}\int_{-\infty}^{x}f(t)\,dt=f(x)\] となります. 統計では,累積分布関数の値を \(\small p\) とするとき, \[\small F(x)=\int_{-\infty}^xf(t)\,dt=p\] を満たす \(\small x\) を求める場面が頻出します. これは,累積分布関数の逆関数を考えることになります. このようなときのために, p分位数を求める関数が用意されています. たとえば,第一四分位数は, \[\small F(x)=\int_{-\infty}^{x}f(x)\,dx=1/4\] を満たす\(\small x\) のことです. 四分位数に限らず, 任意の \(\small p~(0\leq p\leq 1)\) に対して, \(\small p\) を与えて上式を満たす \(\small x\) の値を 求めることができます. 確率変数 \(\small X\) の確率密度関数を \(\small f(x)\) とすると, 平均や分散は次の式で定義されます. \[\small \begin{align*} (平均)\quad &E[X]=\int_{-\infty}^{\infty}xf(x)\,dx\\ (分散)\quad &V[X]=\int_{-\infty}^{\infty}(x-E[X])^2f(x)\,dx \end{align*}\] 標準偏差は \(\small \sigma[X]=\sqrt{V[X]}\) です. 平均を \(\small \mu\) とするとき, 分散を \(\small (X-\mu)^2\) の平均とみて, \(\small V[X]=E[(X-\mu)^2]\) と表す場合もあります. 多くの場合は以上のものだけで議論が進んで行きますが, 他に「歪度」や「尖度」というものもあります. それぞれ次の式で定義されます. \[\small \begin{align*} (歪度)\quad &E\bigg[\left(\frac{X-\mu}{\sigma}\right)^3\bigg]\\ (尖度)\quad &E\bigg[\left(\frac{X-\mu}{\sigma}\right)^4\bigg]-3 \end{align*} \] 歪度は分布の対称度を表す指標とされ, 歪度が \(\small 0\) のときは左右対称であり, 正のときは右側に裾が長く(左側にこぶがある), 負のときは左側に裾が長い(右側にこぶがある)分布になります. 尖度は分布の尖り具合を表す指標とされ, 尖度が \(\small 0\) のときは正規分布と同じような尖り具合で, 正のときは正規分布よりも尖っており, 負のときは正規分布よりも鈍い分布になります. Maximaでの記号は, 基本的に「(統計量)_(確率分布の名称)」で表され, 正規分布(normal distribution) N(\(\small m,s^2\)) の場合は次のように表されます. \(\small m\) は平均,\(\small s^2\) は分散です. したがって,\(\small s\) は標準偏差です.
|
|
|
|
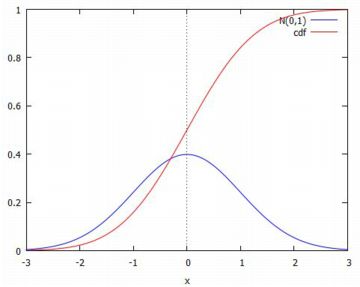
標準正規分布 前述のMaximaのコマンドを利用すれば, 具体的な関数の式を知らなくても計算を進めていくことができますが, 以下では どのような関数で計算されているのかを確認しておきましょう. 確率分布への理解を深めるには,計算結果だけはなく, その値がどのようにして得られているのかを理解しておくことも必要です. 以下では標準正規分布 N(0,1) の場合を考えます( 参照). |
|
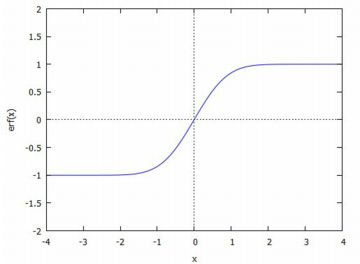
関連する諸関数 標準正規分布は,正規分布 N(m,s) で \(\small m=0, s=1\) の場合なので, \(\small f(x)={\rm pdf\_normal}(x,0,1)\), \(\small F(x)={\rm cdf\_normal}(x,0,1)\) です. そして,\(\small F(x)=p\) を満たす \(\small x\) は, \(\small x={\rm quantile\_normal}(p,0,1)\) と表されます. 具体的な関数は, \[\small f(x)=\frac1{\sqrt{2\pi}}e^{-\frac{x^2}{2}}\] が確率密度関数であり, 累積分布関数はこの関数を積分することで得られます. \[\small F(x)=\frac1{\sqrt{2\pi}}\int_{-\infty}^{x}e^{-\frac{t^2}{2}}\,dt\] 下図は,2つのパッケージ「distrib」と「descriptive」を読み込んでから 実行しています.
なお,最新版のMaximaでは,(%i8)の仮定をしなくても(%o9)が表示されます. \begin{gather*}\small \frac12+\frac12{\rm erf} \left(\frac{x}{\sqrt{2}}\right)=p\\ \small {\rm erf} \left(\frac{x}{\sqrt{2}}\right)=2p-1\\ \small \frac{x}{\sqrt{2}}={\rm erf}^{-1}(2p-1)\\ \small \therefore\quad x=\sqrt{2}\,{\rm erf}^{-1}(2p-1) \end{gather*} 「assume」を利用すると,いろいろな仮定を置くことができます. どのような仮定がなされているかは「facts()」により確認できます. 仮定を削除するには「forget」を利用します. (%i13)では,「facts()」により何も表示されないので, 仮定が削除されたことが分かります.
|
|
|
|
グラフの確認 次に,グラフを確認しておきましょう.
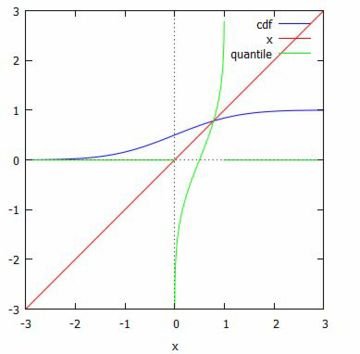
次に,累積分布曲線とp分位数を表す関数のグラフを描画してみましょう. 下図のように,直線 \(\small y=x\) に関して対称になり, 逆関数であることが分かります.
|
|
|
|
幾つかの値の確認 今度は,具体的な値を確認してみましょう. 統計解析では \(\small {\rm P} (|X|\leq \alpha)=0.95\) を満たす \(\small \alpha\) の値が頻出します. N(0,1)の確率密度曲線が左右対称であることから, このような \(\small \alpha\) は \(\small {\rm P} (X\leq \alpha)=0.975\) を満たすので, 要するに \(\small F(\alpha)=0.975\) となる値を求めれば良いわけです. それは,累積分布関数の逆関数なので,p分位数を表す関数を利用すると \(\small \alpha={\rm quantile\_normal} (0.975,0,1)\) により求められます.
下図では,確率密度関数 \(\small f(x)\) の \(\small \alpha\) までの積分を実際に計算して0.975になることを 確認しています.「%」は,直前の結果である(%o22)のことであり, 「minf」は \(\small -\infty\) のことです.
|
|
|
|
平均と分散 次に,平均や分散の値を求めてみましょう.
次に,分散について同様のことを行ってみましょう.
以上のように,数式処理ソフト「Maxima」を利用すると, 統計に関する数表が手元に無くても統計分析を行うことができます. それはエクセルやRでも同様ですが, 「数式処理」機能を利用することで, いろいろな統計量の定義に基づいた積分計算を行うことができます. その計算も交えながら学習していくと, 統計に関する理解がより深まるのではないかと思われます. |
|
|
|
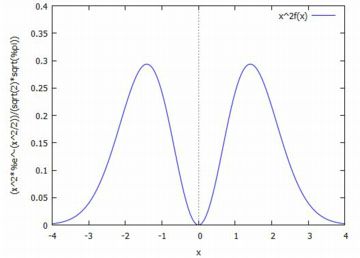
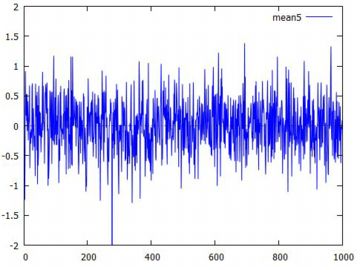
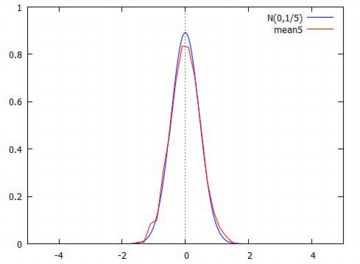
平均の分布 標準正規分布 N(0,1) から無作為抽出した大きさ \(\small n\) の標本の 平均は,平均が 0, 分散は \(\small 1/n\) の正規分布にしたがいます. 乱数を利用して,このことを実際に確かめてみましょう.
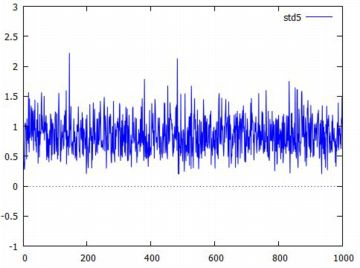
下図は,標準偏差についてみたものです. 標準偏差は,1 を中心に多くは \(\small 0.5\sim 1.5\) の間の 値になっているようです.
以上のもとでグラフを描画したのが下図になります. 5個平均の分布はN(0,1/5)にしたがうので, その確率密度関数のグラフも描画しました. 重なっているのが分かります.この場合の確率密度関数は, \(\small {\rm pdf}\_{\normal}(x,0,1/\sqrt{5})\) です.
|
|
|
|
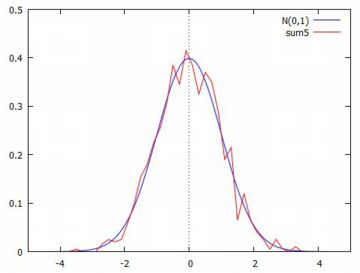
無限分割可能分布 \(\small X_1,X_2,\ldots,X_n\) をN(0,1)にしたがう互いに独立な 確率変数とすると,\(\small X_1+X_2+\cdots+X_n\) は 正規分布N(0,1/n)にしたがいます.これを逆に考えると, \(\small X_1,X_2,\ldots,X_n\) をN(0,1/n)にしたがう互いに独立な 確率変数とすると,\(\small X_1+X_2+\cdots+X_n\) は 標準正規分布N(0,1)にしたがうことになります. つまり,標準正規分布にしたがう確率変数を \(\small Z\) とすると, \(\small Z\) は,正規分布N(0,1/n)にしたがう確率変数の \(\small n\) 個の 和で表されることになります.\(\small n\) は任意の自然数です. このように,一つの確率変数 \(\small Z\) を, 別な確率変数の和で表すことができるとき,確率変数 \(\small Z\) の したがう確率分布を「無限分割可能分布」といいます. このことを実際に確かめてみましょう.
グラフを描くと下図のようになり,標準正規分布のグラフと 重なっているのが分かります.
|
|
|
|
他の確率分布との関係 いろいろな確率分布の中で, 標準正規分布N(0,1)は基本的で重要な確率分布です. それは,他のいろいろな確率分布と密接に関わっているからです. 以下では,\(\small Z,W\) や \(\small Z_1,Z_2,\ldots,Z_n\) は標準正規分布にしたがうものとします.
|
|
|
|
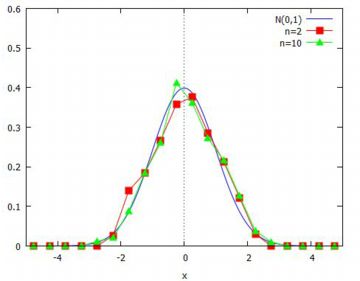
中心極限定理 中心極限定理は,次のような定理です. 確率変数 \(\small X_1,X_2,\ldots,X_n\) が 平均 \(\small \mu\),分散 \(\small \sigma^2\) を持つ 同一の確率分布にしたがうものとする.このとき, その平均を \(\small \bar{X}=\frac1{n}(X_1+X_2+\cdots+X_n)\) とすると, 次のことが成り立つ. \[\small \begin{align*} &\lim_{n\to\infty} {\rm P} \left(\frac{\bar{X}-\mu}{\sigma/\sqrt{n}}\leq a\right)\\ &=\frac1{\sqrt{2\pi}}\int_{-\infty}^{a} e^{-\frac{x^2}{2}}\,dx\end{align*}\] これは,要するに, 「平均や分散が存在するような分布であれば, それがどのような分布であっても, 標本数を大きくしていけば, 標本平均を標準化した値の分布は標準正規分布N(0,1)に近づいていく」 という内容の定理です. 統計での多くの計算が結局は正規分布に帰着するのは, この定理によるところが大きいといえるでしょう. 統計を理解する上では, この定理の意味を正しく把握することが重要です. そのためには「どのような分布」でも, 標本数を大きくすると「平均の分布が正規分布に近づいていく」 ことを実感として理解することが必要です. ここでは,一様分布について以下のことを行ってみましょう.
以上の準備のもとで,(%i38)では \(\small n=2, 10\) の場合の 平均の値を1000個用意した場合の分布図です.
他の確率分布にしたがう場合も, 同じ手順で標準化した場合のグラフや, 標準化しない場合のグラフを確認することができます. 標準化の場合の修正箇所は下記の通りです.
|
| 中心極限定理については,下記も参照してください. |
|
|
|
カイ二乗分布 中心極限定理が成り立つような確率分布では, その分布から抽出した標本平均を標準化すると標準正規分布に近づいていきますが, 分散の分布はどのようになっているのでしょうか. この分散の分布を調べるときに必要になるのが \(\small \chi^2\) 分布です 参照). |
|
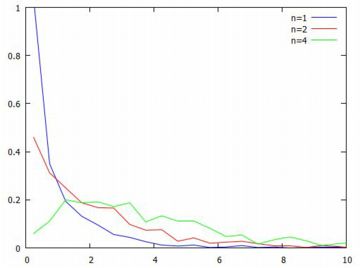
正規乱数のニ乗和 分散がどのような分布になるのか, 標準正規分布N(0,1)から \(\small n\) 個の標本を抽出して試してみましょう. \(\small X_1, X_2, \ldots, X_n\) を抽出したとすると, \(\small (平均) \mu=E[X]=0\) となるので, \(\small V[X]=\frac1{n}\sum_{k=1}^{n}X_i^2\) を調べることになります. まず,\(\small X_1^2+X_2^2+\cdots+X_n^2\) について調べてみましょう. この式がしたがう分布が自由度 \(\small n\) のカイニ乗分布です. 「desciptive」と「distrib」は読み込み済みとします.
以上のもとで,正規乱数の2乗和の度数分布は次のように描画されます. \(\small n=1, 2, 4\) のときの1000個のデータの分布です.
|
|
|
|
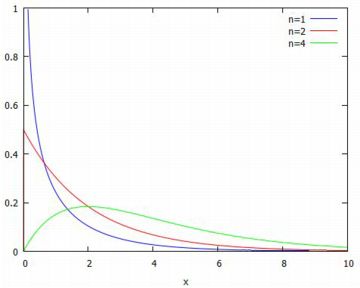
確率密度関数 ここで,\(\small \chi^2\) 分布の確率密度関数の定義式を確認してみましょう.
確率変数 \(\small X\) が標準正規分布N(0,1)にしたがえば, その確率密度関数は次の式で表されます. \[\small f(x)=\frac{1}{\sqrt{2\pi}}e^{-\frac{x^2}{2}}\] 自由度が \(\small n=1\) の場合は \(\small X^2\) の確率密度関数を 考えることになりますが, それは \(\small Y=X^2\) とおくとき,累積分布を考えると \[\small P(Y\leq x)=\int_{0}^{x}g(y)\,dy\] を満たすような関数 \(\small g(y)\) を求めることになります. \[\begin{align} \small P(Y\leq x) &\small =P(X^2\leq x)\\ &\small =P(-\sqrt{x}\leq X\leq \sqrt{x})\\ &\small =2P(0\leq X\leq \sqrt{x})\\ &\small =2P(X\leq \sqrt{x})-1 \end{align}\] これは,積分で表すと \[\small \int_{0}^{x}g(y)\,dy =2\int_{-\infty}^{\sqrt{x}}f(t)\,dt-1\] ということなので,両辺を \(\small x\) で微分すると 微積分の基本定理と合成関数の微分法により \[\begin{align*} \small g(x) &\small =2f(\sqrt{x})(\sqrt{x})'\\ &\small =2\cdot\frac1{\sqrt{2\pi}}e^{-\frac{x}{2}}\cdot\frac1{2\sqrt{x}}\\ &\small =\frac1{\sqrt{2\pi}}x^{-\frac12}e^{-\frac{x}{2}} \end{align*}\] となります. ここで,\(\small \sqrt{2}=2^{\frac12}\) であり, ガンマ関数の性質から \(\small \Gamma\left(\frac12\right)=\sqrt{\pi}\) であることを利用すると, この関数は次のように表すことができます. \[\small g(x)=\frac{1}{2^{\frac12}\Gamma\left(\frac12\right)}x^{\frac12-1}e^{-\frac{x}{2}}\] 以上のことを \(\small X_1^2+X_2^2+\cdots+X_n^2\) で考えて得られるのが, 前述した \(\small \chi^2\) 分布の確率密度関数です. 周知のように,\(\small Z_1, Z_2, \ldots, Z_n\) がN(0,1)にしたがえば, その平方和 \(\small Z_1^2+Z_2^2+\cdots+Z_n^2\) は自由度 \(\small n\) の \(\small \chi^2\) 分布にしたがいます.このことを利用すると, \(\small X_1, X_2, \ldots, X_n\) がN(\(\mu\),\(\small \sigma^2\))にしたがえば, それを標準化した \[\begin{align*} \small \left(\frac{X_1-\mu}{\sigma}\right)^2 &\small +\cdots+\left(\frac{X_n-\mu}{\sigma}\right)^2\\ &\small =\frac1{\sigma^2}\sum_{k=1}^{n}(X_i-\mu)^2\end{align*}\] は自由度 \(\small n\) の \(\small \chi^2\) 分布にしたがいます. 母平均 \(\small \mu\) が不明のとき, それを標本平均 \(\small \bar{X}\) で置きかえた \[\small \frac1{\sigma^2}\sum_{k=1}^{n}(X_i-\bar{X})^2\] は自由度 \(\small n-1\) の \(\small \chi^2\) 分布にしたがうことが 知られています. |
|
|
|
平均と分散 前項で述べたように,自由度 \(\small n\) のカイ二乗分布の 確率密度関数 \(\small f(x)\) は, \[\small \frac1{2^{\frac{n}{2}}\Gamma\left(\frac{n}{2}\right)} x^{\frac{n}{2}-1}e^{-\frac{x}{2}}\quad (x\gt 0)\] です. (%o21)で示されるガンマ分布の確率密度関数は, Maximaのソースファイルが置かれているフォルダー内にある「distrib.mac」の中で, 次の式で記述されています. \[\small \frac{x^{a-1}e^{-x/b}}{b^a\Gamma(a)}\] したがって,カイ自乗分布の確率密度関数は,ガンマ分布の確率密度関数の \(\small a=\frac{n}{2}, b=2\) の場合に相当します. つまり,この式を \(\small h(x,a,b)\) で表すことにすると, \(\small g(x)=h(x,\frac{n}{2},2)\) ということです. そこで,最初にガンマ分布について考えてみましょう. 簡単のため \(\small b=1\) の場合を考えると, \[\small h(x,a,1)=\frac1{\Gamma(a)}x^{a-1}e^{-x}\] であり,ガンマ関数の定義式の被積分関数が含まれています. そのことを利用すると,\(\small b=1\) のときの平均は次のようになります. \[\begin{align*} \small E(X) &\small =\int_0^{\infty}xh(x,a,1)\,dx\\ &\small =\frac1{\Gamma(a)}\int_0^{\infty}x^{(a+1)-1}e^{-x}\,dx\\ &\small =\frac{\Gamma(a+1)}{\Gamma(a)}\\ &\small =\frac{a\Gamma(a)}{\Gamma(a)}=a \end{align*}\] ここでは, ガンマ関数 の \(\small \Gamma(x+1)=x\Gamma(x)\) という性質を利用しています. 同様にすると, \[\begin{align*} \small E(X^2) &\small =\int_0^{\infty}x^2h(x,a,1)\,dx\\ &\small =\frac1{\Gamma(a)}\int_0^{\infty}x^{(a+2)-1}e^{-x}\,dx\\ &\small =\frac{\Gamma(a+2)}{\Gamma(a)}\\ &\small =\frac{(a+1)a\Gamma(a)}{\Gamma(a)}\\ &\small =a(a+1) \end{align*}\] となるので,\(\small b=1\) のときの分散は次のようになります. \[\begin{align*} \small V(X) &\small =E(X^2)-E(x)^2\\ &\small =a(a+1)-a^2=a \end{align*}\] 次に,一般の \(\small h(x,a,b)\) の場合を考えると, \[\small h(x,a,b)=\frac1{b^a\Gamma(a)}x^{a-1}e^{-\frac{x}{b}}\] において,\(\small \frac{x}{b}=t\) とおくと \(\small x=bt\) である ことから, \[\begin{align} \small h(x,a,b) &\small =\frac1{b^a\Gamma(a)}(bt)^{a-1}e^{-t}\\ &\small =\frac1{b}\cdot\frac1{\Gamma(a)}t^{a-1}e^{-t}\\ &\small =\frac1{b}h(t,a,1) \end{align}\] となり,\(\small b=1\) の場合の式で表すことができます. したがって,この \(\small x=bt\) という置換を行うと, 一般の場合の平均は \[\begin{align*} \small E(X) &\small =\int_0^{\infty}xh(x,a,b)\,dx\\ &\small =\int_0^{\infty}bt\cdot \frac1{b}h(t,a,1)\,bdt\\ &\small =b\int_0^{\infty}t\cdot h(t,a,1)\,dt=ab \end{align*}\] 同様にすると \[\begin{align*} \small E(X^2) &\small =\int_0^{\infty}x^2h(x,a,b)\,dx\\ &\small =\int_0^{\infty}(bt)^2\cdot \frac1{b}h(t,a,1)\,bdt\\ &\small =b^2\int_0^{\infty}t^2\cdot h(t,a,1)\,dt\\ &\small =a(a+1)b^2 \end{align*}\] となるので,一般のガンマ分布の分散は \[\begin{align} \small V(X) &\small =E(X^2)-E(X)^2\\ &\small =a(a+1)b^2-(ab)^2\\ &\small =ab^2 \end{align}\] となります.ガンマ分布で \(\small a=\frac{n}{2}, b=2\) の場合が カイ二乗分布なので,自由度が \(\small n\) のカイ二乗分布の平均と分散は, 結局は次のような簡単な式で表されます. \[\small E(X)=n,\quad V(X)=2n\] |
|
|
|
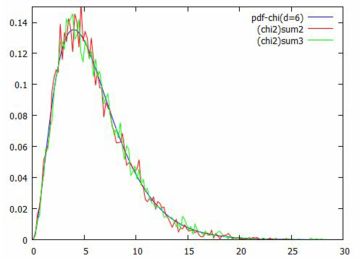
無限分割可能分布 \(\small Z_i~(1\leq i\leq n)\) をN(0,1)にしたがう互いに独立な 確率変数とすると, \(\small Z_1^2+Z_2^2+\cdots+Z_n^2\) は自由度 \(\small n\) の カイ自乗分布にしたがいます.一般に, \(\small X_i~(1\leq i\leq n)\) が自由度 \(\small k\) のカイ二乗分布にしたがう互いに独立な確率変数とすると, \(\small X_1+X_2+\cdots+X_n\) は自由度 \(\small nk\) の カイニ乗分布にしたがいます. これを逆にいうと,\(\small X\) が自由度 \(\small N\) の カイニ乗分布にしたがい \(\small N=nk\) と因数分解できれば, \(\small X\) は自由度 \(\small k\) のカイ二乗分布にしたがう 互いに独立な確率変数 \(\small X_i~(1\leq i\leq n)\) に対して, \[\small X=X_1+X_2+\cdots+X_n\] と \(\small n\) 個の確率変数の和に分解できることになります. 以上のことを,\(\small N=6=2\cdot 3\) の場合に 実際に確かめてみましょう. 前述のことから,\(\small X\) が自由度6のカイ二乗分布にしたがえば, \(\small X\) はそれぞれ自由度が2の3個の確率変数と, 自由度が3の2個の確率変数の和で表せることになります.
以上もとで,グラフを描画したのが下図です. 2つのヒストグラムが, 自由度6のカイ二乗分布の確率密度関数のグラフと 重なっているのが分かります.
|
|
|
|
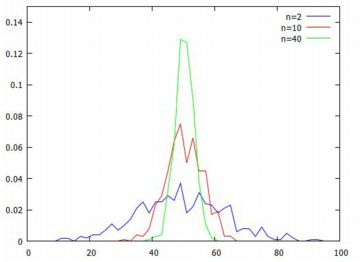
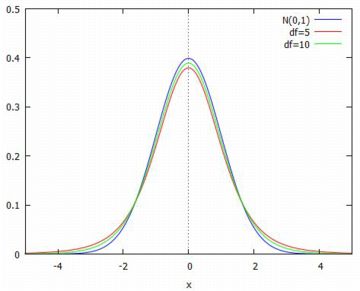
t分布 正規分布N(\(\small \mu,\sigma^2)\)から抽出した大きさ \(\small n\) の 標本を \(\small X_1, X_2, \ldots, X_n\) とすると, 周知のように標本平均 \(\small \bar{X}=\frac1{n}(X_1+X_2+\cdots+X_n)\) は 正規分布N(\(\small \mu,\sigma^2/n\))にしたがいます. 最初に,このことを確認してみましょう. 以下では,「distrib」と「descriptive」は読み込み済みとします 参照).
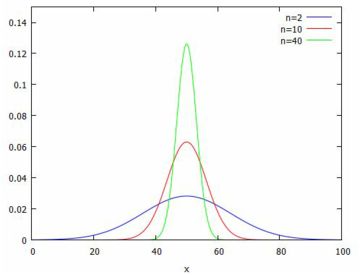
以上の準備のもとに,(%i20)で \(\small n=2, 10, 40\) の場合の 平均からなる500個の値を, 2点刻みの度数分布にしてグラフ化したものが下図です.
|
|
|
|
以上の分布は,母集団となる正規分布の分散 \(\small \sigma^2\) の
値が分かっている場合です.その場合は,標準化を行った
\[\small Z=\frac{\bar{X}-\mu}{\sigma/\sqrt{n}}\]
は,標準正規分布N(0,1)にしたがいます.
母分散 \(\small \sigma^2\) が不明のときは標本の値から推定するしかありません.
それは,周知のように不偏分散 \(\small U^2\) で推定することができます.
その場合に,標準化に相当する式は
\[\small T=\frac{\bar{X}-\mu}{U/\sqrt{n}}\]
となります.この値はどのような分布をするのでしょうか.
\(\small T\) の分子・分母を \(\small \sigma/\sqrt{n}\) で割ると,
\[\begin{align*}\small
T&=\frac{\frac{\bar{X}-\mu}{\sigma/\sqrt{n}}}
{\frac{U/\sqrt{n}}{\sigma/\sqrt{n}}}\\
&=\frac{Z}{U/\sigma}
\end{align*}\]
となります.さらに,分母は,
\[\small\begin{align*}
&\frac{U}{\sigma}=\sqrt{\frac{U^2}{\sigma^2}}\\
&=\sqrt{\frac1{n-1}\cdot\frac1{\sigma^2}\sum_{k=1}^{n}(X_i-\bar{X})^2}
\end{align*}\]
となります.
ここで,\(\small X_1,X_2,\ldots,X_n\) は
N(\(\small \mu,\sigma^2\))から抽出した標本とします.
その場合,\(\small (X_i-\mu)/\sigma\) はN(0,1)にしたがうので,
\(\small \frac1{\sigma^2}\sum_{k=1}^n(X_i-\mu)^2\) は
自由度 \(\small n\) の \(\small \chi^2\) 分布にしたがいますが,
\(\small \mu\) を \(\small \bar{X}\) で置きかえた
\[\small \frac1{\sigma^2}\sum_{k=1}^n(X_i-\bar{X})^2\]
は,自由度 \(\small n-1\) の \(\small \chi^2\) 分布にしたがうことが
知られています.
つまり,\(\small U/\sigma\) は,
自由度 \(\small n-1\) の \(\small \chi^2\) 分布にしたがう統計量を,
その統計量の自由度である \(\small n-1\) で割って平方根を取った値です.
したがって,\(\small T\) がどのような分布にしたがうかを調べるには,
標準正規分布N(0,1)にしたがう統計量を \(\small Z\),
自由度 \(\small n\) の \(\small \chi^2\) 分布にしたがう統計量を
\(\small Y\) とするとき,
\[\small T=\frac{Z}{\sqrt{\frac{Y}{n}}}\]
がどのような分布にしたがうかを調べればよいことになります.
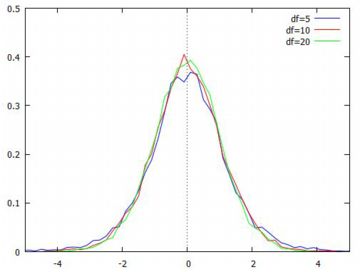
この式が自由度 \(\small n\) の \(\small t\) 分布の定義式です.
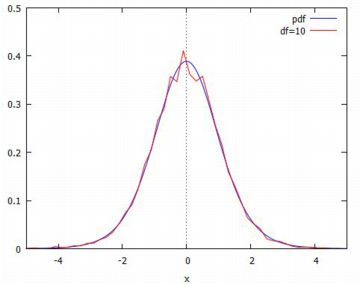
以上のことを実際に行ったのが下記です.
|
|
|
|
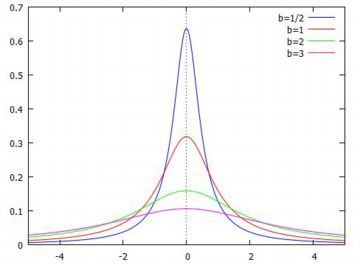
コーシー分布 中心極限定理は, 平均と分散が存在するような同一分布から標本を抽出した場合です. それらが存在しない分布とは,どのような分布なのでしょうか. それは,要するに,平均と分散の定義式 である広義積分が存在しない場合の分布です. そのような分布として,コーシー分布が知られています. 平均と分散のみならず,歪度も尖度も存在しません 参照). |
|
確率密度関数 コーシー分布の確率密度関数は,次の式で表されます. この式で表されるコーシー分布を Cauchy(a,b) で表すことにします. \[\small f(x,a,b)=\frac{1}{\pi}\cdot\frac{b}{(x-a)^2+b^2}\]
|
|
|
|
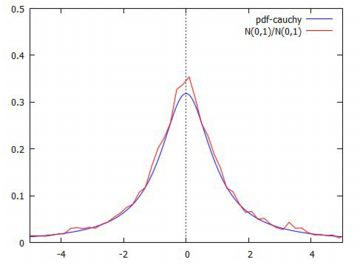
N(0,1)の比 Cauchy(0,1)は標準正規分布N(0,1)とも深く関わっています. 今,\(\small Z, W\) をN(0,1)にしたがう互いに独立な確率変数とします. それらの比 \(\small X=Z/W\) を考えると,\(\small X\) が したがう確率分布がコーシー分布 Cauchy(0,1) なのです. その理由は簡単です. \(\small W^2\) は自由度 1 のカイ自乗分布にしたがうので, \[\small X=\frac{Z}{\sqrt{W^2/1}}\] とみることができ,\(\small t\) 分布の定義より \(\small X\) は自由度1の \(\small t\) 分布にしたがいます. したがって,前述のことから,その確率密度関数は Cauchy(0,1) と一致します. 以上のことを,N(0,1)からの乱数を利用して実際に確かめてみましょう. wxMaximaを利用します.
|
|
|
|
平均と分散 コーシー分布の平均と分散が存在しないことは,実際に積分してみれば分かります. 簡単のため, \(\small f(x,0,1)\) で考えます.
次に,\(\small xf(x,0,1), x^2f(x,0,1)\) の不定積分を求めると (%o11)(%o12)のようになり, いずれも \(\small x\to\pm\infty\) のときの極限値は存在しない ことが分かります.ここで,平均の計算式は \[\small \int_{-\infty}^{\infty}xf(x,0,1)\,dx =\int_{-\infty}^{\infty}\frac{x}{\pi(x^2+1)}\,dx\] で表されます.被積分関数が奇関数なので, 一見すると積分結果は 0 としがちですが, \[\small\begin{align*} (右辺) &=\lim_{\substack{b\to\infty\\ a\to-\infty}}\bigg[\frac1{2\pi}\log(x^2+1)\bigg]_a^b\\ &=\lim_{\substack{b\to\infty\\ a\to-\infty}}\bigg[\frac1{2\pi}\log\frac{b^2+1}{a^2+1}\bigg]_a^b \end{align*}\] となり,この積分の値(つまり平均)は存在しません. たとえば \(\small a=-tb~(t\gt 0)\) の場合は \[\small\begin{align*} (右辺) &=\lim_{b\to\infty}\frac1{2\pi}\log\frac{b^2+1}{t^2b^2+1}\\ &=\frac1{2\pi}\log\frac1{t^2}=-\frac1{\pi}\log{t} \end{align*}\] となるので,これは \(\small (-\infty, \infty)\) の全ての値を取り得ます. 平均が存在しないので,分散・歪度・尖度はいずれも存在しません. なお,(%i9)により確率密度関数の不定積分が存在するので, コーシー分布の累積分布関数は次のように逆正接関数を用いて 表されます. \[\begin{align*} \small {\rm cdf}\_{\rm cauchy}(x,0,1) &\small =\int_{-\infty}^{x}f(x,0,1)\,dx\\ &\small =\frac1{\pi}\big[{\rm arctan}(x)\big]_{-\infty}^{x}\\ &\small =\frac1{\pi}\left({\rm \arctan}(x)+\frac{\pi}{2}\right)\\ &\small =\frac12+\frac1{\pi}{\rm \arctan}(x) \end{align*}\] したがって,この逆関数としての「quantile_cauchy(x,0,1)」は, \[\begin{gather*} \small \frac12+\frac1{\pi}{\rm \arctan}(y)=x\\ \small {\rm arctan}(y)=\pi\left(x-\frac{1}{2}\right)\\ \small \therefore\quad y=\tan\pi\left(x-\frac{1}{2}\right) \end{gather*}\] となり,正接関数になります. このことから,コーシー分布の四分位数の値は, たとえば次のようになります. \[\begin{align*} &\small {\rm quantile}\_{\rm cauchy}(1/4,0,1)=-1\\ &\small {\rm quantile}\_{\rm cauchy}(1/2,0,1)=0\\ &\small {\rm quantile}\_{\rm cauchy}(3/4,0,1)=1 \end{align*}\] |
|
|
|
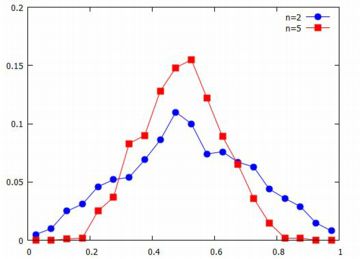
標本平均の分布 このような分布にしたがう乱数の標本平均を取ると, それはどのようになっているのでしょうか.これまで見てきた分布では, 平均を取る個数を増やすと標本平均は母平均の周りに集まってきます. しかし,コーシー分布では母平均自体が存在しません. そこで,前と同じようにして,標本平均からなるリストを作って, その様子を調べてみましょう.
このように,block関数を利用すると,繰り返しや条件分岐などを含む いろいろな処理を行わせることができます.
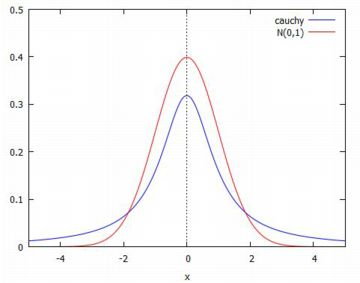
ここで,幾つかの事項を,標準正規分布と比較してみましょう. 下図は,標準正規分布 N(0,1) のグラフとコーシー分布のグラフを重ね合わせています.
|
|
|
|
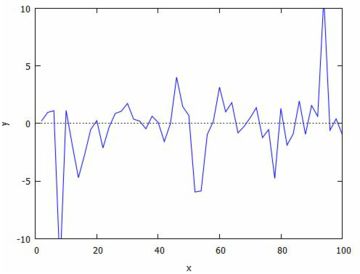
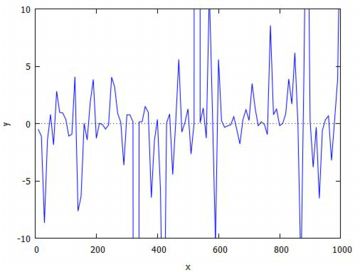
次に,標本平均を取る個数を増やすごとに,標本平均の値がどのように変化して
いくかを調べてみましょう.
同様のことを標準正規分布で調べるには, 「random_cauchy(0,1)」を「random_normal(0,1)」に 変更するだけです.自分で試してみてください.
|
|
|
|
次に,作成した平均のヒストグラムをみてみましょう.
「TeXmacs+Maxima」ではヒストグラムの区分の際に
エラーが生じるので,wxMaximaを利用します.
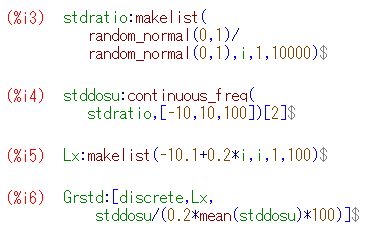
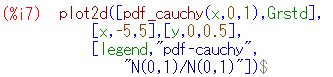
コーシー分布にしたがう乱数「random_cauchy(0,1)」を利用して
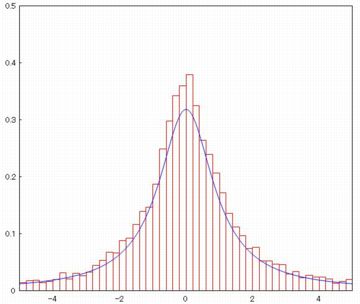
下図の(%i16)により5個の乱数の平均からなる10000個の要素を持つリストを作成し,
区間 [-5, 5] を50等分してヒストグラムを描画したものです.
「draw」パッケージを利用して,
(%i18)によりコーシー分布の確率密度曲線「pdf_cauchy(x,0,1)」も
同時に描画しました.
以上のことから,コーシー分布は, 確率密度関数の形は正規分布と似ていますが, 正規分布とは全く異なる分布であることが分かります. コーシー分布のように, 平均も分散も存在しないような分布を含む確率分布に, 「安定分布」と呼ばれるものがあります. コーシー分布は安定分布です. 詳しくは「こちら」を参照してください. |
|
|
|
参照したWebサイト コーシー分布の箇所では,下記のサイトを参照させていただきました. |
|
|